
Hacks.Mozilla.Org: Improving Performance in Firefox and Across the Web with Speedometer 3
In collaboration with the other major browser engine developers, Mozilla is thrilled to announce Speedometer 3 today. Like previous versions of Speedometer, this benchmark measures what we think matters most for performance online: responsiveness. But today’s release is more open and more challenging than before, and is the best tool for driving browser performance improvements that we’ve ever seen.
This fulfills the vision set out in December 2022 to bring experts across the industry together in order to rethink how we measure browser performance, guided by a shared goal to reflect the real-world Web as much as possible. This is the first time the Speedometer benchmark, or any major browser benchmark, has been developed through a cross-industry collaboration supported by each major browser engine: Blink, Gecko, and WebKit. Working together means we can build a shared understanding of what matters to optimize, and facilitates broad review of the benchmark itself: both of which make it a stronger lever for improving the Web as a whole.
And we’re seeing results: Firefox got faster for real users in 2023 as a direct result of optimizing for Speedometer 3. This took a coordinated effort from many teams: understanding real-world websites, building new tools to drive optimizations, and making a huge number of improvements inside Gecko to make web pages run more smoothly for Firefox users. In the process, we’ve shipped hundreds of bug fixes across JS, DOM, Layout, CSS, Graphics, frontend, memory allocation, profile-guided optimization, and more.
We’re happy to see core optimizations in all the major browser engines turning into improved responsiveness for real users, and are looking forward to continuing to work together to build performance tests that improve the Web.
The post Improving Performance in Firefox and Across the Web with Speedometer 3 appeared first on Mozilla Hacks - the Web developer blog.
Mozilla Thunderbird: Thunderbird for Android / K-9 Mail: February 2024 Progress Report

Welcome to a new report on the progress of transforming K-9 Mail into Thunderbird for Android. I hope you’ve enjoyed the extra day in February. We certainly did and used this opportunity to release a new stable version on February 29.
If you’re new to this series or the unusually long February made you forget what happened the previous month, you might want to check out January’s progress report.
New stable releaseWe spent most of our time in February getting ready for a new stable release – K-9 Mail 6.800. That mostly meant fixing bugs and usability issues reported by beta testers. Thanks to everyone who tested the app and reported bugs 
Read all about the new release in our blog post Towards Thunderbird for Android – K-9 Mail 6.800 Simplifies Adding Email Accounts.
What’s next?With the new account setup being mostly done, we’ll concentrate on the following two areas.
Material 3The question of whether to update the user interface to match the design used by the latest Android version seems to have always split the K-9 Mail user base. One group prefers that we work on adding new features instead. The other group wants their email app of choice to look similar to the apps that ship with Android.
Never updating the user interface to the latest design is not really an option. At some point all third-party libraries we’re using will only support the latest platform design. Not updating those libraries is also not an option because Android itself is constantly changing and requires app/library updates just to keep existing functionality working.
I think we found a good balance by not being the first ones to update to Material 3. By now a lot of other app developers have done so and countless bugs related to Material 3 have been found and fixed. So it’s a good time for us to start switching to Android’s latest design system now.
We’re currently still in a research phase to figure out what parts of the app need changing. Once that’s done, we’ll change the base theme and fix up the app screen by screen. You will be able to follow along by becoming a beta tester and installing K-9 Mail 6.9xx beta versions once those become available.
Android 14 compatibilityK-9 Mail is affected by a couple of changes that were introduced with Android 14. We’ve started to look into which parts of the app need to be updated to be able to target Android 14.
We’ve already identified these:
- Schedule exact alarms are denied by default – For some reason Google decided to also apply this change to apps targeting Android 13. We already mentioned this in our November/December 2023 progress report in the section “Push Not Working On Android 14”.
- Restrictions to implicit and pending intents – This affects the way we communicate with the crypto provider app (OpenKeychain) when using OpenPGP.
Our current plan is to include the necessary changes in updates to the K-9 Mail 6.8xx line.
Community Contributions- S Tanveer Hussain submitted a pull request to update the information about third-party libraries in K-9 Mail’s About screen (#7601)
- GitHub user LorenzHo provided a patch to not focus the recipient input field when the Compose screen was opened using a mailto: URI (#7623). Unfortunately, this change had to be backed out later because of unintended side effects. But we’re hopeful a modified version of this change will make it into the app soon.
Thank you for your contributions!
ReleasesIn February 2024 we published a new stable release:
- K-9 Mail v6.800 (2024-02-29)
… and the following beta versions:
- K-9 Mail v6.715 (beta) (2024-02-01)
- K-9 Mail v6.716 (beta) (2024-02-13)
- K-9 Mail v6.717 (beta) (2024-02-16)
The post Thunderbird for Android / K-9 Mail: February 2024 Progress Report appeared first on The Thunderbird Blog.
Adrian Gaudebert: Killing two birds with one deck in Dawnmaker
Let's face it: Dawnmaker still has some important flaws. We're aware of that, and we are working on those flaws. One of the biggest remaining problem with the game was that one of its core mechanics, the oppression of the Smog, was… well, not explained at all. If you didn't have a developer behind your back to tell you, there was almost no way you could understand it.
What's the oppression of the Smog, you ask? It is the fact that the Smog gets stronger the more the game progresses, and thus makes you consume luminoil faster. It's a simple formula that grows every time you shuffle your deck of cards: when that happens, your luminoil consumption increases by the level of your aerostation. We tried a few, small things to explain that mechanism: we added an animation to the Smog, making it grow darker and closer to your city, when the oppression increases. We also had a line in the luminoil tooltip showing how much luminoil is consumed by this oppression. But that was not nearly enough, and I started thinking about how to solve this with a complex UI inspired by Frostpunk. I am glad I did not go with that, as it would have been a nightmare to implement, and I now believe it would not have helped much.
 <figcaption>
<figcaption>
I sure am glad I did not try to implement this…
</figcaption>So, while I was busy not solving this problem, another one got to the front: the progression issue. You see, we have been struggling a lot with the meta progression we offer in Dawnmaker. We've made attempts at doing it Slay the Spire-like, with a map of limited paths and rewards after each stop. That doesn't work very well, the roguelike structure (the progression on the world map) around an already roguelike structure (a single region / city) was weird and sometimes frustrating. So we started thinking about doing it differently, more like Hades does it with its mirror. There would be a new resource that you'd gain after securing each region, and that resource could be spent in order to improve your starting party, making each new region a tad easier to secure.
We like this idea, but it causes another problem: if the game gets easier and easier, there will come a point when it will become boring, as the challenge will be lost. We thus need to have a progression in the difficulty just as we have one in the player's strength. Hades does that with the Heat system, where you can choose how you increase the challenge each time you play. We cannot easily do something similar, so I once again started thinking about a complex question: how can we increase the difficulty of the game? What levers to we have to do that in a way that is challenging and doesn't feel too artificial or frustrating? There's an easy answer to that: the length of the game and the number of lighthouses, which we use in the currently called "Discovery" game, where we increase both the level to reach and the number of lighthouses to repair in order to win a game as you progress on the map. But that is not enough for a long-term progression, as it would quickly feel completely artificial. Luckily, there was another feature we could use, and did not: the oppression of the Smog. That is were those two problems converged, and led me to a single solution solving both: turning the Smog's behavior into a deck of cards.

Using cards to represent the Smog's behavior increases the affordance of the game: Smog cards look like buildings cards, and they sort of work like them. It's a card that has an effect, that you can read at any time, and because it uses the same wording, abilities and display as the buildings, it's easy to interpret it. Changing the behavior simply means changing the card, and we can do a whole bunch of animations there to show that happening. We can also add tooltips around those elements to explain them further. That's a first big win! Now the second one is that we create and handle those decks in our content editor, and we can create as many cards and decks as we want. There we have it: near infinite difficulty progression, simply by making different Smog cards, and assembling them differently in various decks!
Note that we haven't done anything like that yet. So far we have only reproduced the previous system with cards. But the potential is here: when we start working on the meta progression, we can be confident that we'll have the tools to make the difficulty progress as well.
We definitely killed two nasty, vicious flying creatures with one deck. Neat!
This piece was initially sent out to the readers of our newsletter. Wanna join in on the fun? Head out to Dawnmaker's presentation page and fill the form. You'll receive regular stories about how we're making this game, the latest news of its development, as well as an exclusive access to Dawnmaker's alpha version!
The Rust Programming Language Blog: Announcing Rustup 1.27.0
The rustup team is happy to announce the release of rustup version 1.27.0. Rustup is the recommended tool to install Rust, a programming language that is empowering everyone to build reliable and efficient software.
If you have a previous version of rustup installed, getting rustup 1.27.0 is as easy as stopping any programs which may be using Rustup (e.g. closing your IDE) and running:
$ rustup self updateRustup will also automatically update itself at the end of a normal toolchain update:
$ rustup updateIf you don't have it already, you can get rustup from the appropriate page on our website.
What's new in rustup 1.27.0This long-awaited Rustup release has gathered all the new features and fixes since April 2023. These changes include improvements in Rustup's maintainability, user experience, compatibility and documentation quality.
Also, it's worth mentioning that Dirkjan Ochtman (djc) and rami3l (rami3l) have joined the team and are coordinating this new release.
At the same time, we have granted Daniel Silverstone (kinnison) and 二手掉包工程师 (hi-rustin) their well-deserved alumni status in this release cycle. Kudos for your contributions over the years and your continuous guidance on maintaining the project!
The headlines for this release are:
-
Basic support for the fish shell has been added. If you're using fish, PATH configs for your Rustup installation will be added automatically from now on.
Please note that this will only take effect on installation, so if you have already installed Rustup on your machine, you will need to reinstall it. For example, if you have installed Rustup via rustup.rs, simply follow rustup.rs's instructions again; if you have installed Rustup using some other method, you might want to reinstall it using that same method.
-
Rustup support for loongarch64-unknown-linux-gnu as a host platform has been added. This means you should be able to install Rustup via rustup.rs and no longer have to rely on loongnix.cn or self-compiled installations.
Please note that as of March 2024, loongarch64-unknown-linux-gnu is a "tier 2 platform with host tools", so Rustup is guaranteed to build for this platform. According to Rust's target tier policy, this does not imply that these builds are also guaranteed to work, but they often work to quite a good degree and patches are always welcome!
Full details are available in the changelog!
Rustup's documentation is also available in the rustup book.
ThanksThanks again to all the contributors who made rustup 1.27.0 possible!
- Anthony Perkins (acperkins)
- Tianqi (airstone42)
- Alex Gaynor (alex)
- Alex Hudspith (alexhudspith)
- Alan Somers (asomers)
- Brett (brettearle)
- Burak Emir (burakemir)
- Chris Denton (ChrisDenton)
- cui fliter (cuishuang)
- Dirkjan Ochtman (djc)
- Dezhi Wu (dzvon)
- Eric Swanson (ericswanson-dfinity)
- Prikshit Gautam (gautamprikshit1)
- hev (heiher)
- 二手掉包工程师 (hi-rustin)
- Kamila Borowska (KamilaBorowska)
- klensy (klensy)
- Jakub Beránek (Kobzol)
- Kornel (kornelski)
- Matt Harding (majaha)
- Mathias Brossard (mbrossard)
- Christian Thackston (nan60)
- Ruohui Wang (noirgif)
- Olivier Lemasle (olivierlemasle)
- Chih Wang (ongchi)
- Pavel Roskin (proski)
- rami3l (rami3l)
- Robert Collins (rbtcollins)
- Sandesh Pyakurel (Sandesh-Pyakurel)
- Waffle Maybe (WaffleLapkin)
- Jubilee (workingjubilee)
- WÁNG Xuěruì (xen0n)
- Yerkebulan Tulibergenov (yerke)
- Renovate Bot (renovate)
The Rust Programming Language Blog: crates.io: Download changes
Like the rest of the Rust community, crates.io has been growing rapidly, with download and package counts increasing 2-3x year-on-year. This growth doesn't come without problems, and we have made some changes to download handling on crates.io to ensure we can keep providing crates for a long time to come.
The ProblemThis growth has brought with it some challenges. The most significant of these is that all download requests currently go through the crates.io API, occasionally causing scaling issues. If the API is down or slow, it affects all download requests too. In fact, the number one cause of waking up our crates.io on-call team is "slow downloads" due to the API having performance issues.
Additionally, this setup is also problematic for users outside of North America, where download requests are slow due to the distance to the crates.io API servers.
The SolutionTo address these issues, over the last year we have decided to make some changes:
Starting from 2024-03-12, cargo will begin to download crates directly from our static.crates.io CDN servers.
This change will be facilitated by modifying the config.json file on the package index. In other words: no changes to cargo or your own system are needed for the changes to take effect. The config.json file is used by cargo to determine the download URLs for crates, and we will update it to point directly to the CDN servers, instead of the crates.io API.
Over the past few months, we have made several changes to the crates.io backend to enable this:
-
We announced the deprecation of "non-canonical" downloads, which would be harder to support when downloading directly from the CDN.
-
We changed how downloads are counted. Previously, downloads were counted directly on the crates.io API servers. Now, we analyze the log files from the CDN servers to count the download requests.
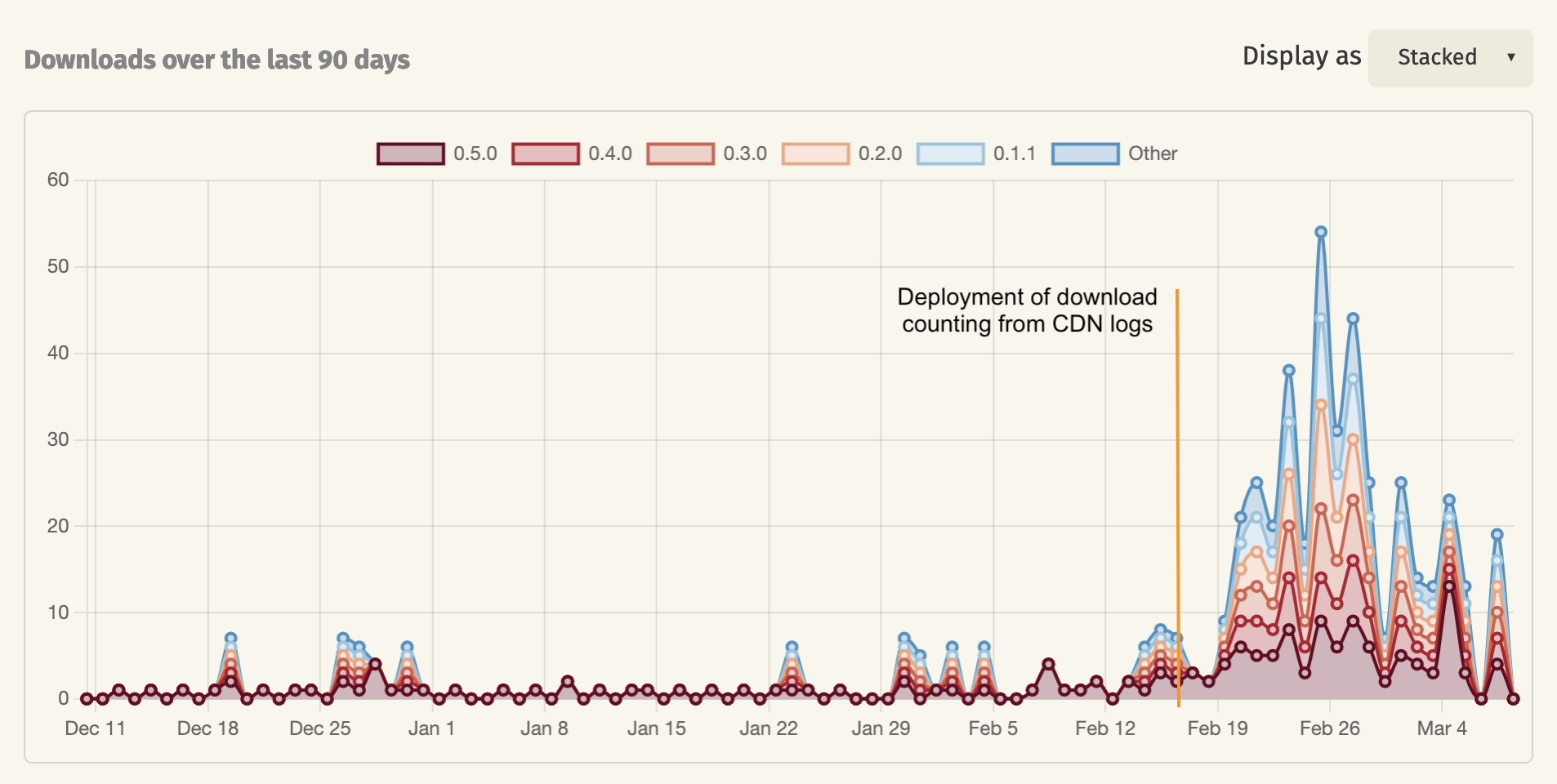
The latter change has caused the download numbers of most crates to increase, as some download requests were not counted before. Specifically, crates.io mirrors were often downloading directly from the CDN servers already, and those downloads had previously not been counted. For crates with a lot of downloads these changes will be barely noticeable, but for smaller crates, the download numbers have increased quite a bit over the past few weeks since we enabled this change.
Expected OutcomesWe expect these changes to significantly improve the reliability and speed of downloads, as the performance of the crates.io API servers will no longer affect the download requests. Over the next few weeks, we will monitor the performance of the system to ensure that the changes have the expected effects.
We have noticed that some non-cargo build systems are not using the config.json file of the index to build the download URLs. We will reach out to the maintainers of those build systems to ensure that they are aware of the change and to help them update their systems to use the new download URLs. The old download URLs will continue to work, but these systems will be missing out on the potential performance improvement.
We are excited about these changes and believe they will greatly improve the reliability of crates.io. We look forward to hearing your feedback!
Don Marti: privacy: I’d buy that for $20!
How much extra should you pay, or would you end up having to pay, to get privacy from surveillance ads? This is my attempt to come up with a high number for surveillance advertising’s impact on the content economy—the actual ad-supported information, entertainment, or other resource that that advertising is paying for. For now I’m going to make the most pro-surveillance assumptions, to try to come up with a high bound for the price of privacy.
To start with, total advertising, in all media, in the USA is about $960 per person which works out to a convenient $80 per month being spent on ads intended to reach you. So let’s start with the $80 and assume (to be as friendly as possible to the surveillance side…)
All advertisers prefer maximum surveillance
All ads are surveillance ads unless interfered with by privacy tools
Surveillance ads are 2x as valuable as non-surveillance ads
People who make content (writers, photographers, artists, musicians, editors…) get a similar large share of revenue from advertising spending as from other ways of supporting their work.
So, if you can somehow get total privacy protection, ads that reach you are worth only $40 per month total, instead of $80. Or, more realistically, if you can get halfway protected, your privacy is costing the content creators of the world $20 per month minus whatever goes to the intermediaries. That’s real money, but it’s on the scale of a few subscriptions or a fraction of an ISP bill, not privacy breaks the Internet economy as we know it money. According to one survey, the average US household spends $61/month on streaming video services. That’s per household, not per person, so at an average household size of 2.5, streaming alone is about $24 a person. could use some numbers for music, news and other services here too.
You might not want to agree with those three assumptions. Some ad money still gets spent on non-surveillance advertising, and surveillance advertising might not be twice as valuable as surveillance advertising in every medium. And different ways of supporting content have different transaction costs. If I install privacy tools that cost the surveillance business $100 in ad revenue per year, and at the same time I buy a subscription to 404 Media for $100 per year, I’m pretty sure I’m paying for a lot more content than the ads would have. The stack of service providers needed to run a subscription service takes a smaller bite of the subscription money than the ad agency/adtech stack takes of the ad money. And the publisher/intermediary split is always worse than it looks. Many of the publishers that show up in adtech’s reckoning of its impact are so-called made for advertising (MFA) sites, or sites that just run copyright-infringing or AI generated content. When a surveillance firm makes claims about ads supporting content, a lot of the ad money they count as the publisher’s share is not funding any new material at all.
Thomas Baekdal wrote, for every one person you could convince to subscribe, donate, become a member, or support you on Patreon…you would need 10,000 visitors to make the same amount from advertising. Or to put that into perspective, with only 100 subscribers, I could make the same amount of money as I used to earn from having one million visitors. It doesn’t look like you need to add $4 to your monthly subscription budget, to balance things out, every time you improve your privacy protection by 10%—that’s more of an unrealistically high estimate if you want to be on the safe side. A more realistic view on the impact of privacy tech is in Targeted advertising, platform competition and privacy. Making both personalized and non-personalized options available will make more money for the publishers, so publishers are better off letting the privacy people have privacy as a fair choice—so the privacy fraction of the audience is protected from being followed elsewhere in a way that drives down ad rates—while the personalized ads option remains available for those who want it.
The bigger problem is that platform companies that sit between advertiser and publisher are steadily chickenizing the companies on both sides of the ad market. Jakob Nielsen pointed out the problem for search engines back in 2006:
In the long run, every time companies increase the value of their online businesses, they end up handing over all that added value to the search engines. Any gain is temporary; once competing sites improve their profit-per-visitor enough to increase their search bids, they’ll drive up everybody’s cost of traffic.
Today, the problem continues in search, but also applies to big retail and social platforms. Direct to consumer brands must pay rent to platforms, and both brands and publishers are indirectly micromanaged by and for large platform companies, like drivers for Uber or Amazon. So it seems like there’s a big win available from antitrust cases. Putting a price on privacy is probably backwards. It would make more sense for legit sellers to promote and even pay for privacy tools among good customers, just for the fraud protection benefits. Money that a customer spends taking their kids to a bogus event advertised on social media can’t be spent on legit products or services. Brands that need to reach a high-privacy early adopter group are going to have some interesting post-surveillance options.
Something that’s harder to measure is that companies may be over-advertising to the point of inefficiency because advertising is (with extra, unwanted, surveillance in place) more measurable than other ways to spend company money. The direct mail saying is list, offer, package—you can get the highest returns by targeting the best-performing list of people, then by making a better product and/or a better price, and finally by improving the actual mail piece. If privacy goes up to the point where optimizing the list is harder to do, then the company has more incentive to invest in “offer” (product features, quality, service, price) and “package” (content marketing and ad creative).
One of the unconventional aspects of the open source trend of the 1990s/early 2000s was that open source companies like Red Hat were willing to say that they wanted the software market to be smaller in total. Most investors don’t like to hear that especially for an established industry. But a smaller, more restricted advertising industry in total might be more valuable to advertisers and consumers, by driving some investment into product improvements that are higher in value than, but less measurable than, advertising.
Bonus linksHow Google Blew Up Its Open Culture and Compromised Its Product
The Tech Industry Doesn’t Understand Consent
We’re not Meta support: State AGs tell Zuck to fix rampant account takeover problem
Tracking ads industry faces another body blow in the EU
Now the EU is asking questions about Meta’s ‘pay or be tracked’ consent model
Meta’s pay-or-consent model hides ‘massive illegal data processing ops’: lawsuit
Platforms are selling your work to AI vendors with impunity. They need to stop.
Wendy’s says ‘dynamic’ pricing won’t tack surge pricing onto your nuggets
Don’t let Reddit monetize your knowledge just so Google can train its AI
The Rentier Economy, Vulture Capital, and Enshittification
Google Reportedly Paying News Outlets to Unleash an Avalanche of AI Slop
If Online Ads Feel More Annoying, It’s Because They Are
It’s MFA Freedom Day! Celebrate By Fixing Your Supply Chain
Avast fined $16.5 million for ‘privacy’ software that actually sold users’ browsing data
Fake Funeral Live Stream Scams Are All Over Facebook
DTC Brands Are Trying Email, Since Social Alone Won’t Cut It
Wladimir Palant: Numerous vulnerabilities in Xunlei Accelerator application
Xunlei Accelerator (迅雷客户端) a.k.a. Xunlei Thunder by the China-based Xunlei Ltd. is a wildly popular application. According to the company’s annual report 51.1 million active users were counted in December 2022. The company’s Google Chrome extension 迅雷下载支持, while not mandatory for using the application, had 28 million users at the time of writing.
I’ve found this application to expose a massive attack surface. This attack surface is largely accessible to arbitrary websites that an application user happens to be visiting. Some of it can also be accessed from other computers in the same network or by attackers with the ability to intercept user’s network connections (Man-in-the-Middle attack).
It does not appear like security concerns were considered in the design of this application. Extensive internal interfaces were exposed without adequate protection. Some existing security mechanisms were disabled. The application also contains large amounts of third-party code which didn’t appear to receive any security updates whatsoever.
I’ve reported a number of vulnerabilities to Xunlei, most of which allowed remote code execution. Still, given the size of the attack surface it felt like I barely scratched the surface.
Last time Xunlei made security news, it was due to distributing a malicious software component. Back then it was an inside job, some employees turned rouge. However, the application’s flaws allowed the same effect to be easily achieved from any website a user of the application happened to be visiting.
Contents- What is Xunlei Accelerator?
- The built-in web browser
- The main application
- The XLLite application
- Plugin management
- Outdated components
- Reporting the issues
Wikipedia lists Xunlei Limited’s main product as a Bittorrent client, and maybe a decade ago it really was. Today however it’s rather difficult to describe what this application does. Is it a download manager? A web browser? A cloud storage service? A multimedia client? A gaming platform? It appears to be all of these things and more.
It’s probably easier to think of Xunlei as an advertising platform. It’s an application with the goal of maximizing profits through displaying advertising and selling subscriptions. As such, it needs to keep the users on the platform for as long as possible. That’s why it tries to implement every piece of functionality the user might need, while not being particularly good at any of it of course.
So there is a classic download manager that will hijack downloads initiated in the browser, with the promise of speeding them up. There is also a rudimentary web browser (two distinctly different web browsers in fact) so that you don’t need to go back to your regular web browser. You can play whatever you are downloading in the built-in media player, and you can upload it to the built-in storage. And did I mention games? Yes, there are games as well, just to keep you occupied.
Altogether this is a collection of numerous applications, built with a wide variety of different technologies, often implementing competing mechanisms for the same goal, yet trying hard to keep the outward appearance of a single application.
The built-in web browser The trouble with custom Chromium-based browsersCompanies love bringing out their own web browsers. The reason is not that their browser is any better than the other 812 browsers already on the market. It’s rather that web browsers can monetize your searches (and, if you are less lucky, also your browsing history) which is a very profitable business.
Obviously, profits from that custom-made browser are higher if the company puts as little effort into maintenance as possible. So they take the open source Chromium, slap their branding on it, maybe also a few half-hearted features, and they call it a day.
Trouble is: a browser has a massive attack surface which is exposed to arbitrary web pages (and ad networks) by definition. Companies like Mozilla or Google invest enormous resources into quickly plugging vulnerabilities and bringing out updates every six weeks. And that custom Chromium-based browser also needs updates every six weeks, or it will expose users to known (and often widely exploited) vulnerabilities.
Even merely keeping up with Chromium development is tough, which is why it almost never happens. In fact, when I looked at the unnamed web browser built into the Xunlei application (internal name: TBC), it was based on Chromium 83.0.4103.106. Being released in May 2020, this particular browser version was already three and a half years old at that point. For reference: Google fixed eight actively exploited zero-day vulnerabilities in Chromium in the year 2023 alone.
Among others, the browser turned out to be vulnerable to CVE-2021-38003. There is this article which explains how this vulnerability allows JavaScript code on any website to gain read/write access to raw memory. I could reproduce this issue in the Xunlei browser.
Protections disabledIt is hard to tell whether not having a pop-up blocker in this browser was a deliberate choice or merely a consequence of the browser being so basic. Either way, websites are free to open as many tabs as they like. Adding --autoplay-policy=no-user-gesture-required command line flag definitely happened intentionally however, turning off video autoplay protections.
It’s also notable that Xunlei revives Flash Player in their browser. Flash Player support has been disabled in all browsers in December 2020, for various reasons including security. Xunlei didn’t merely decide to ignore this reasoning, they shipped Flash Player 29.0.0.140 (released in April 2018) with their browser. Adobe support website lists numerous Flash Player security fixes published after April 2018 and before end of support.
Censorship includedInterestingly, Xunlei browser won’t let users visit the example.com website (as opposed to example.net). When you try, the browser redirects you to a page on static.xbase.cloud. This is an asynchronous process, so chances are good that you will catch a glimpse of the original page first.

Automated translation of the text: “This webpage contains illegal or illegal content and access has been stopped.”
As it turns out, the application will send every website you visit to an endpoint on api-shoulei-ssl.xunlei.com. That endpoint will either accept your choice of navigation target or instruct to redirect you to a different address. So when to navigate to example.com the following request will be sent:
POST /xlppc.blacklist.api/v1/check HTTP/1.1 Content-Length: 29 Content-Type: application/json Host: api-shoulei-ssl.xunlei.com {"url":"http://example.com/"}And the server responds with:
{ "code": 200, "msg": "ok", "data": { "host": "example.com", "redirect": "https://static.xbase.cloud/file/2rvk4e3gkdnl7u1kl0k/xappnotfound/#/unreach", "result": "reject" } }Interestingly, giving it the address http://example.com./ (note the trailing dot) will result in the response {"code":403,"msg":"params error","data":null}. With the endpoint being unable to handle this address, the browser will allow you to visit it.
Native APIIn an interesting twist, the Xunlei browser exposed window.native.CallNativeFunction() method to all web pages. Calls would be forwarded to the main application where any plugin could register its native function handlers. When I checked, there were 179 such handlers registered, though that number might vary depending on the active plugins.
Among the functions exposed were ShellOpen (used Windows shell APIs to open a file), QuerySqlite (query database containing download tasks), SetProxy (configure a proxy server to be used for all downloads) or GetRecentHistorys (retrieve browsing history for the Xunlei browser).
My proof-of-concept exploit would run the following code:
native.CallNativeFunction("ShellOpen", "c:\\windows\\system32\\calc.exe");This would open the Windows Calculator, just as you’d expect.
Now this API was never meant to be exposed to all websites but only to a selected few very “trusted” ones. The allowlist here is:
[ ".xunlei.com", "h5-pccloud.onethingpcs.com", "h5-pccloud.test.onethingpcs.com", "h5-pciaas.onethingpcs.com", "h5-pccloud.onethingcloud.com", "h5-pccloud-test.onethingcloud.com", "h5-pcxl.hiveshared.com" ]And here is how access was being validated:
function isUrlInDomains(url, allowlist, frameUrl) { let result = false; for (let index = 0; index < allowlist.length; ++index) { if (url.includes(allowlist[index]) || frameUrl && frameUrl.includes(allowlist[index])) { result = true; break; } } return result; }As you might have noticed, this doesn’t actually validate the host name against the list but looks for substring matches in the entire address. So https://malicious.com/?www.xunlei.com is also considered a trusted address, allowing for a trivial circumvention of this “protection.”
Getting into the Xunlei browserNow most users hopefully won’t use Xunlei for their regular browsing. These should be safe, right?
Unfortunately not, as there is a number of ways for webpages to open the Xunlei browser. The simplest way is using a special thunderx:// address. For example, thunderx://eyJvcHQiOiJ3ZWI6b3BlbiIsInBhcmFtcyI6eyJ1cmwiOiJodHRwczovL2V4YW1wbGUuY29tLyJ9fQ== will open the Xunlei browser and load https://example.com/ into it. From the attacker’s point of view, this approach has a downside however: modern browsers ask the user for confirmation before letting external applications handle addresses.
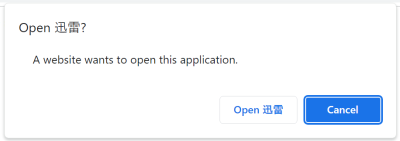
There are alternatives however. For example, the Xunlei browser extension (28 million users according to Chrome Web Store) is meant to pass on downloads to the Xunlei application. It could be instrumented into passing on thunderx:// links without any user interaction however, and these would immediately open arbitrary web pages in the Xunlei browser.
More ways to achieve this are exposed by the XLLite application’s API which is introduced later. And that’s likely not even the end of it.
The fixesWhile Xunlei never communicated any resolution of these issues to me, as of Xunlei Accelerator 12.0.8.2392 (built on February 2, 2024 judging by executable signatures) several changes have been implemented. First of all, the application no longer packages Flash Player. It still activates Flash Player if it is installed on the user’s system, so some users will still be exposed. But chances are good that this Flash Player installation will at least be current (as much as software can be “current” three years after being discontinued).
The isUrlInDomains() function has been rewritten, and the current logic appears reasonable. It will now only check the allowlist against the end of the hostname, matches elsewhere in the address won’t be accepted. So this now leaves “only” all of the xunlei.com domain with access to the application’s internal APIs. Any cross-site scripting vulnerability anywhere on this domain will again put users at risk.
The outdated Chromium base appears to remain unchanged. It still reports as Chromium 83.0.4103.106, and the exploit for CVE-2021-38003 still succeeds.
The browser extension 迅雷下载支持 also received an update, version 3.48 on January 3, 2024. According to automated translation, the changelog entry for this version reads: “Fixed some known issues.” The fix appears to be adding a bunch of checks for the event.isTrusted property, making sure that the extension can no longer be instrumented quite as easily. Given these restrictions, just opening the thunderx:// address directly likely has higher chances of success now, especially when combined with social engineering.
The main application Outdated Electron frameworkThe main Xunlei application is based on the Electron framework. This means that its user interface is written in HTML and displayed via the Chromium web browser (renderer process). And here again it’s somewhat of a concern that the Electron version used is 83.0.4103.122 (released in June 2020). It can be expected to share most of the security vulnerabilities with a similarly old Chromium browser.
Granted, an application like that should be less exposed than a web browser as it won’t just load any website. But it does work with remote websites, so vulnerabilities in the way it handles web content are an issue.
Cross-site scripting vulnerabilitiesBeing HTML-based, the Xunlei application is potentially vulnerable to cross-site scripting vulnerabilities. For most part, this is mitigrated by using the React framework. React doesn’t normally work with raw HTML code, so there is no potential for vulnerabilities here.
Well, normally. Unless dangerouslySetInnerHTML property is being used, which you should normally avoid. But it appears that Xunlei developers used this property in a few places, and now they have code displaying messages like this:
$createElement("div", { staticClass: "xly-dialog-prompt__text", domProps: { innerHTML: this._s(this.options.content) } })If message content ever happens to be some malicious data, it could create HTML elements that will result in execution of arbitrary JavaScript code.
How would malicious data end up here? Easiest way would be via the browser. There is for example the MessageBoxConfirm native function that could be called like this:
native.CallNativeFunction("MessageBoxConfirm", JSON.stringify({ title: "Hi", content: `<img src="x" onerror="alert(location.href)">`, type: "info", okText: "Ok", cancelVisible: false }));When executed on a “trusted” website in the Xunlei browser, this would make the main application display a message and, as a side-effect, run the JavaScript code alert(location.href).
Impact of executing arbitrary code in the renderer processElectron normally sandboxes renderer processes, making certain that these have only limited privileges and vulnerabilities are harder to exploit. This security mechanism is active in the Xunlei application.
However, Xunlei developers at some point must have considered it rather limiting. After all, their user interface needed to perform lots of operations. And providing a restricted interface for each such operation was too much effort.
So they built a generic interface into the application. By means of messages like AR_BROWSER_REQUIRE or AR_BROWSER_MEMBER_GET, the renderer process can instruct the main (privileged) process of the application to do just about anything.
My proof-of-concept exploit successfully abused this interface by loading Electron’s shell module (not accessible to sandboxed renderers by regular means) and calling one of its methods. In other words, the Xunlei application managed to render this security boundary completely useless.
The (lack of) fixesLooking at Xunlei Accelerator 12.0.8.2392, I could not recognize any improvements in this area. The application is still based on Electron 83.0.4103.122. The number of potential XSS vulnerabilities in the message rendering code didn’t change either.
It appears that Xunlei called it a day after making certain that triggering messages with arbitrary content became more difficult. I doubt that it is impossible however.
The XLLite application Overview of the applicationThe XLLite application is one of the plugins running within the Xunlei framework. Given that I never created a Xunlei account to see this application in action, my understanding of its intended functionality is limited. Its purpose however appears to be integrating the Xunlei cloud storage into the main application.
As it cannot modify the main application’s user interface directly, it exposes its own user interface as a local web server, on a randomly chosen port between 10500 and 10599. That server essentially provides static files embedded in the application, all functionality is implemented in client-side JavaScript.
Privileged operations are provided by a separate local server running on port 21603. Some of the API calls exposed here are handled by the application directly, others are forwarded to the main application via yet another local server.
I originally got confused about how the web interface accesses the API server, with the latter failing to implement CORS correctly – OPTION requests don’t get a correct response, so that only basic requests succeed. It appears that Xunlei developers didn’t manage to resolve this issue and instead resorted to proxying the API server on the user interface server. So any endpoints available on the API server are exposed by the user interface server as well, here correctly (but seemingly unnecessarily) using CORS to allow access from everywhere.
So the communication works like this: the Xunlei application loads http://127.0.0.1:105xx/ in a frame. The page then requests some API on its own port, e.g. http://127.0.0.1:105xx/device/now. When handling the request, the XLLite application requests http://127.0.0.1:21603/device/now internally. And the API server handler within the same process responds with the current timestamp.
This approach appears to make little sense. However, it’s my understanding that Xunlei also produces storage appliances which can be installed on the local network. Presumably, these appliances run identical code to expose an API server. This would also explain why the API server is exposed to the network rather than being a localhost-only server.
The “pan authentication”With quite a few API calls having the potential to do serious damage or at the very least expose private information, these need to be protected somehow. As mentioned above, Xunlei developers chose not to use CORS to restrict access but rather decided to expose the API to all websites. Instead, they implemented their own “pan authentication” mechanism.
Their approach of generating authentication tokens was taking the current timestamp, concatenating it with a long static string (hardcoded in the application) and hashing the result with MD5. Such tokens would expire after 5 minutes, apparently an attempt to thwart replay attacks.
They even went as far as to perform time synchronization, making sure to correct for deviation between the current time as perceived by the web page (running on the user’s computer) and by the API server (running on the user’s computer). Again, this is something that probably makes sense if the API server can under some circumstances be running elsewhere on the network.
Needless to say that this “authentication” mechanism doesn’t provide any value beyond very basic obfuscation.
Achieving code execution via plugin installationThere are quite a few interesting API calls exposed here. For example, the device/v1/xllite/sign endpoint would sign data with one out of three private RSA keys hardcoded in the application. I don’t know what this functionality is used for, but I sincerely hope that it’s as far away from security and privacy topics as somehow possible.
There is also the device/v1/call endpoint which is yet another way to open a page in the Xunlei browser. Both OnThunderxOpt and OpenNewTab calls allow that, the former taking a thunderx:// address to be processed and the latter a raw page address to be opened in the browser.
It’s fairly obvious that the API exposes full access to the user’s cloud storage. I chose to focus my attention on the drive/v1/app/install endpoint however, which looked like it could do even more damage. This endpoint in fact turned out to be a way to install binary plugins.
I couldn’t find any security mechanisms preventing malicious software to be installed this way, apart from the already mentioned useless “pan authentication.” However, I couldn’t find any actual plugins to use as an example. In the end I figured out that a plugin had to be packaged in an archive containing a manifest.yaml file like the following:
ID: Exploit Title: My exploit Description: This is an exploit Version: 1.0.0 System: - OS: windows ARCH: 386 Service: ExecStart: Exploit.exe ExecStop: Exploit.exeThe plugin would install successfully under Thunder\Profiles\XLLite\plugin\Exploit\1.0.1\Exploit but the binary wouldn’t execute for some reason. Maybe there is a security mechanism that I missed, or maybe the plugin interface simply isn’t working yet.
Either way, I started thinking: what if instead of making XLLite run my “plugin” I would replace an existing binary? It’s easy enough to produce an archive with file paths like ..\..\..\oops.exe. However, the Go package archiver used here has protection against such path traversal attacks.
The XLLite code deciding which folder to put the plugin into didn’t have any such protections on the other hand. The folder is determined by the ID and Version values of the plugin’s manifest. Messing with the former is inconvenient, it being present twice in the path. But setting the “version” to something like ..\..\.. achieved the desired results.
Two complications:
- The application to be replaced cannot be running or the Windows file locking mechanism will prevent it from being replaced.
- The plugin installation will only replace entire folders.
In the end, I chose to replace Xunlei’s media player for my proof of concept. This one usually won’t be running and it’s contained in a folder of its own. It’s also fairly easy to make Xunlei run the media player by using a thunderx:// link. Behold, installation and execution of a malicious application without any user interaction.
Remember that the API server is exposed to the local network, meaning that any devices on the network can also perform API calls. So this attack could not merely be executed from any website the user happened to be visiting, it could also be launched by someone on the same network, e.g. when the user is connected to a public WiFi.
The fixesAs of version 3.19.4 of the XLLite plugin (built January 25, 2024 according to its digital signature), the “pan authentication” method changed to use JSON Web Tokens. The authentication token is embedded within the main page of the user interface server. Without any CORS headers being produced for this page, the token cannot be extracted by other web pages.
It wasn’t immediately obvious what secret is being used to generate the token. However, authentication tokens aren’t invalidated if the Xunlei application is restarted. This indicates that the secret isn’t being randomly generated on application startup. The remaining possibilities are: a randomly generated secret stored somewhere on the system (okay) or an obfuscated hardcoded secret in the application (very bad).
While calls to other endpoints succeed after adjusting authentication, calls to the drive/v1/app/install endpoint result in a “permission denied” response now. I did not investigate whether the endpoint has been disabled or some additional security mechanism has been added.
Plugin management The odditiesXLLite’s plugin system is actually only one out of at least five completely different plugin management systems in the Xunlei application. One other is the main application’s plugin system, the XLLite application is installed as one such plugin. There are more, and XLLiveUpdateAgent.dll is tasked with keeping them updated. It will download the list of plugins from an address like http://upgrade.xl9.xunlei.com/plugin?os=10.0.22000&pid=21&v=12.0.3.2240&lng=0804 and make sure that the appropriate plugins are installed.
Note the lack of TLS encryption here which is quite typical. Part of the issue appears to be that Xunlei decided to implement their own HTTP client for their downloads. In fact, they’ve implemented a number of different HTTP clients instead of using any of the options available via the Windows API for example. Some of these HTTP clients are so limited that they cannot even parse uncommon server responses, much less support TLS. Others support TLS but use their own list of CA certificates which happens to be Mozilla’s list from 2016 (yes, that’s almost eight years old).
Another common issue is that almost all these various update mechanisms run as part of the regular application process, meaning that they only have user’s privileges. How do they manage to write to the application directory then? Well, Xunlei solved this issue: they made the application directory writable with user’s privileges! Another security mechanism successfully dismantled. And there is a bonus: they can store application data in the same directory rather than resorting to per-user nonsense like AppData.
Altogether, you better don’t run Xunlei Accelerator on untrusted networks (meaning: any of them?). Anyone on your network or anyone who manages to insert themselves into the path between you and the Xunlei update server will be able to manipulate the server response. As a result, the application will install a malicious plugin without you even noticing anything.
You also better don’t run Xunlei Accelerator on a computer that you share with other people. Anyone on a shared computer will be able to add malicious components to the Xunlei application, so next time you run it your user account will be compromised.
Example scenario: XLServicePlatformI decided to focus on XLServicePlatform because, unlike all the other plugin management systems, this one runs with system privileges. That’s because it’s a system service and any installed plugins will be loaded as dynamic libraries into this service process. Clearly, injecting a malicious plugin here would result in full system compromise.
The management service downloads the plugin configuration from http://plugin.pc.xunlei.com/config/XLServicePlatform_12.0.3.xml. Yes, no TLS encryption here because the “HTTP client” in question isn’t capable of TLS. So anyone on the same WiFi network as you for example could redirect this request and give you a malicious response.
In fact, that HTTP client was rather badly written, and I found multiple Out-of-Bounds Read vulnerabilities despite not actively looking for them. It was fairly easy to crash the service with an unexpected response.
But it wasn’t just that. The XML response was parsed using libexpat 2.1.0. With that version being released more than ten years ago, there are numerous known vulnerabilities, including a number of critical remote code execution vulnerabilities.
I generally leave binary exploitation to other people however. Continuing with the high-level issues, a malicious plugin configuration will result in a DLL or EXE file being downloaded, yet it won’t run. There is a working security mechanism here: these files need a valid code signature issued to Shenzhen Thunder Networking Technologies Ltd.
But it still downloads. And there is our old friend: a path traversal vulnerability. Choosing the file name ..\XLBugReport.exe for that plugin will overwrite the legitimate bug reporter used by the Xunlei service. And crashing the service with a malicious server response will then run this trojanized bug reporter, with system privileges.
My proof of concept exploit merely created a file in the C:\Windows directory, just to demonstrate that it runs with sufficient privileges to do it. But we are talking about complete system compromise here.
The (lack of?) fixesAt the time of writing, XLServicePlatform still uses its own HTTP client to download plugins which still doesn’t implement TLS support. Server responses are still parsed using libexpat 2.1.0. Presumably, the Out-of-Bounds Read and Path Traversal vulnerabilities have been resolved but verifying that would take more time than I am willing to invest.
The application will still render its directory writable for all users. It will also produce a number of unencrypted HTTP requests, including some that are related to downloading application components.
Outdated componentsI’ve already mentioned the browser being based on an outdated Chromium version, the main application being built on top of an outdated Electron platform and a ten years old XML library being widely used throughout the application. This isn’t by any means the end of it however. The application packages lots of third-party components, and the general approach appears to be that none of them are ever updated.
Take for example the media player XMP a.k.a. Thunder Video which is installed as part of the application and can be started via a thunderx:// address from any website. This is also an Electron-based application, but it’s based on an even older Electron 59.0.3071.115 (released in June 2017). The playback functionality seems to be based on the APlayer SDK which Xunlei provides for free for other applications to use.
Now you might know that media codecs are extremely complicated pieces of software that are known for disastrous security issues. That’s why web browsers are very careful about which media codecs they include. Yet APlayer SDK features media codecs that have been discontinued more than a decade ago as well as some so ancient that I cannot even figure out who developed them originally. There is FFmpeg 2021-06-30 (likely a snapshot around version 4.4.4), which has dozens of known vulnerabilities. There is libpng 1.0.56, which was released in July 2011 and is affected by seven known vulnerabilities. Last but not least, there is zlib 1.2.8-4 which was released in 2015 and is affected by at least two critical vulnerabilities. These are only some examples.
So there is a very real threat that Xunlei users might get compromised via a malicious media file, either because they were tricked into opening it with Xunlei’s video player, or because a website used one of several possible ways to open it automatically.
As of Xunlei Accelerator 12.0.8.2392, I could not notice any updates to these components.
Reporting the issuesReporting security vulnerabilities is usually quite an adventure, and the language barrier doesn’t make it any better. So I was pleasantly surprised to discover XunLei Security Response Center that was even discoverable via an English-language search thanks to the site heading being translated.
Unfortunately, there was a roadblock: submitting a vulnerability is only possible after logging in via WeChat or QQ. While these social networks are immensely popular in China, creating an account from outside China proved close to impossible. I’ve spent way too much time on verifying that.
That’s when I took a closer look and discovered an email address listed on the page as fallback for people who are unable to log in. So I’ve sent altogether five vulnerability reports on 2023-12-06 and 2023-12-07. The number of reported vulnerabilities was actually higher because the reports typically combined multiple vulnerabilities. The reports mentioned 2024-03-06 as publication deadline.
I received a response a day later, on 2023-12-08:
Thank you very much for your vulnerability submission. XunLei Security Response Center has received your report. Once we have successfully reproduced the vulnerability, we will be in contact with you.
Just like most companies, they did not actually contact me again. I saw my proof of concept pages being accessed, so I assumed that the issues are being worked on and did not inquire further. Still, on 2024-02-10 I sent a reminder that the publication deadline was only a month away. I do this because in my experience companies will often “forget” about the deadline otherwise (more likely: they assume that I’m not being serious about it).
I received another laconic reply a week later which read:
XunLei Security Response Center has verified the vulnerabilities, but the vulnerabilities have not been fully repaired.
That was the end of the communication. I don’t really know what Xunlei considers fixed and what they still plan to do. Whatever I could tell about the fixes here has been pieced together from looking at the current software release and might not be entirely correct.
It does not appear that Xunlei released any further updates in the month after this communication. Given the nature of the application with its various plugin systems, I cannot be entirely certain however.
Mozilla Open Policy & Advocacy Blog: Mozilla Mornings: Choice or Illusion? Tackling Harmful Design Practices
The first edition of Mozilla Mornings in 2024 will explore the impact of harmful design on consumers in the digital world and the role regulation can play in addressing such practices.
In the evolving digital landscape, deceptive and manipulative design practices, as well as aggressive personalisation and profiling pose significant threats to consumer welfare, potentially leading to financial loss, privacy breaches, and compromised security.
While existing EU regulations address some aspects of these issues, questions persist about their adequacy in combating harmful design patterns comprehensively. What additional measures are needed to ensure digital fairness for consumers and empower designers who want to act ethically?
To discuss these issues, we are delighted to announce that the following speakers will be participating in our panel discussion:
- Egelyn Braun, Team Leader DG JUST, European Commission
- Estelle Hary, Co-founder, Design Friction
- Silvia de Conca, Amsterdam Law & Technology Institute, Vrije Universiteit Amsterdam
- Finn Myrstad, Digital Policy Director, Norwegian Consumer Council
The event will also feature a fireside chat with MEP Kim van Sparrentak from Greens/EFA.
- Date: Wednesday 20th March 2024
- Location: L42, Rue de la Loi 42, 1000 Brussels
- Time: 08:30 – 10:30 CET
To register, click here.
The post Mozilla Mornings: Choice or Illusion? Tackling Harmful Design Practices appeared first on Open Policy & Advocacy.
Niko Matsakis: Borrow checking without lifetimes
This blog post explores an alternative formulation of Rust’s type system that eschews lifetimes in favor of places. The TL;DR is that instead of having 'a represent a lifetime in the code, it can represent a set of loans, like shared(a.b.c) or mut(x). If this sounds familiar, it should, it’s the basis for polonius, but reformulated as a type system instead of a static analysis. This blog post is just going to give the high-level ideas. In follow-up posts I’ll dig into how we can use this to support interior references and other advanced borrowing patterns. In terms of implementation, I’ve mocked this up a bit, but I intend to start extending a-mir-formality to include this analysis.
Why would you want to replace lifetimes?Lifetimes are the best and worst part of Rust. The best in that they let you express very cool patterns, like returning a pointer into some data in the middle of your data structure. But they’ve got some serious issues. For one, the idea of what a lifetime is rather abstract, and hard for people to grasp (“what does 'a actually represent?”). But also Rust is not able to express some important patterns, most notably interior references, where one field of a struct refers to data owned by another field.
So what is a lifetime exactly?Here is the definition of a lifetime from the RFC on non-lexical lifetimes:
Whenever you create a borrow, the compiler assigns the resulting reference a lifetime. This lifetime corresponds to the span of the code where the reference may be used. The compiler will infer this lifetime to be the smallest lifetime that it can have that still encompasses all the uses of the reference.
Read the RFC for more details.
Replacing a lifetime with an originUnder this formulation, 'a no longer represents a lifetime but rather an origin – i.e., it explains where the reference may have come from. We define an origin as a set of loans. Each loan captures some place expression (e.g. a or a.b.c), that has been borrowed along with the mode in which it was borrowed (shared or mut).
Origin = { Loan } Loan = shared(Place) | mut(Place) Place = variable(.field)* // e.g., a.b.c Defining typesUsing origins, we can define Rust types roughly like this (obviously I’m ignoring a bunch of complexity here…):
Type = TypeName < Generic* > | & Origin Type | & Origin mut Type TypeName = u32 (for now I'll ignore the rest of the scalars) | () (unit type, don't worry about tuples) | StructName | EnumName | UnionName Generic = Type | OriginHere is the first interesting thing to note: there is no 'a notation here! This is because I’ve not introduced generics yet. Unlike Rust proper, this formulation of the type system has a concrete syntax (Origin) for what 'a represents.
Explicit types for a simple programHaving a fully explicit type system also means we can easily write out example programs where all types are fully specified. This used to be rather challenging because we had no notation for lifetimes. Let’s look at a simple example, a program that ought to get an error:
let mut counter: u32 = 22_u32; let p: & /*{shared(counter)}*/ u32 = &counter; // --------------------- // no syntax for this today! counter += 1; // Error: cannot mutate `counter` while `p` is live println!("{p}");Apart from the type of p, this is valid Rust. Of course, it won’t compile, because we can’t modify counter while there is a live shared reference p (playground). As we continue, you will see how the new type system formulation arrives at the same conclusion.
Basic typing judgmentsTyping judgments are the standard way to describe a type system. We’re going to phase in the typing judgments for our system iteratively. We’ll start with a simple, fairly standard formulation that doesn’t include borrow checking, and then show how we introduce borrow checking. For this first version, the typing judgment we are defining has the form
Env |- Expr : TypeThis says, “in the environment Env, the expression Expr is legal and has the type Type”. The environment Env here defines the local variables in scope. The Rust expressions we are looking at for our sample program are pretty simple:
Expr = integer literal (e.g., 22_u32) | & Place | Expr + Expr | Place (read the value of a place) | Place = Expr (overwrite the value of a place) | ...Since we only support one scalar type (u32), the typing judgment for Expr + Expr is as simple as:
Env |- Expr1 : u32 Env |- Expr2 : u32 ----------------------------------------- addition Env |- Expr1 + Expr2 : u32The rule for Place = Expr assignments is based on subtyping:
Env |- Expr : Type1 Env |- Place : Type2 Env |- Type1 <: Type2 ----------------------------------------- assignment Env |- Place = Expr : ()The rule for &Place is somewhat more interesting:
Env |- Place : Type ----------------------------------------- shared references Env |- & Place : & {shared(Place)} TypeThe rule just says that we figure out the type of the place Place being borrowed (here, the place is counter and its type will be u32) and then we have a resulting reference to that type. The origin of that reference will be {shared(Place)}, indicating that the reference came from Place:
&{shared(Place)} Type Computing livenessTo introduce borrow checking, we need to phase in the idea of liveness.1 If you’re not familiar with the concept, the NLL RFC has a nice introduction:
The term “liveness” derives from compiler analysis, but it’s fairly intuitive. We say that a variable is live if the current value that it holds may be used later.
Unlike with NLL, where we just computed live variables, we’re going to compute live places:
LivePlaces = { Place }To compute the set of live places, we’ll introduce a helper function LiveBefore(Env, LivePlaces, Expr): LivePlaces. LiveBefore() returns the set of places that are live before Expr is evaluated, given the environment Env and the set of places live after expression. I won’t define this function in detail, but it looks roughly like this:
// `&Place` reads `Place`, so add it to `LivePlaces` LiveBefore(Env, LivePlaces, &Place) = LivePlaces ∪ {Place} // `Place = Expr` overwrites `Place`, so remove it from `LivePlaces` LiveBefore(Env, LivePlaces, Place = Expr) = LiveBefore(Env, (LivePlaces - {Place}), Expr) // `Expr1` is evaluated first, then `Expr2`, so the set of places // live after expr1 is the set that are live *before* expr2 LiveBefore(Env, LivePlaces, Expr1 + Expr2) = LiveBefore(Env, LiveBefore(Env, LivePlaces, Expr2), Expr1) ... etc ... Integrating liveness into our typing judgmentsTo detect borrow check errors, we need to adjust our typing judgment to include liveness. The result will be as follows:
(Env, LivePlaces) |- Expr : TypeThis judgment says, “in the environment Env, and given that the function will access LivePlaces in the future, Expr is valid and has type Type”. Integrating liveness in this way gives us some idea of what accesses will happen in the future.
For compound expressions, like Expr1 + Expr2, we have to adjust the set of live places to reflect control flow:
LiveAfter1 = LiveBefore(Env, LiveAfter2, Expr2) (Env, LiveAfter1) |- Expr1 : u32 (Env, LiveAfter2) |- Expr2 : u32 ----------------------------------------- addition (Env, LiveAfter2) |- Expr1 + Expr2 : u32We start out with LiveAfter2, i.e., the places that are live after the entire expression. These are also the same as the places live after expression 2 is evaluated, since this expression doesn’t itself reference or overwrite any places. We then compute LiveAfter1 – i.e., the places live after Expr1 is evaluated – by looking at the places that are live before Expr2. This is a bit mind-bending and took me a bit of time to see. The tricky bit here is that liveness is computed backwards, but most of our typing rules (and intution) tends to flow forwards. If it helps, think of the “fully desugared” version of +:
let tmp0 = <Expr1> // <-- the set LiveAfter1 is live here (ignoring tmp0, tmp1) let tmp1 = <Expr2> // <-- the set LiveAfter2 is live here (ignoring tmp0, tmp1) tmp0 + tmp1 // <-- the set LiveAfter2 is live here Borrow checking with livenessNow that we know liveness information, we can use it to do borrow checking. We’ll introduce a “permits” judgment:
(Env, LiveAfter) permits Loanthat indicates that “taking the loan Loan would be allowed given the environment and the live places”. Here is the rule for assignments, modified to include liveness and the new “permits” judgment:
(Env, LiveAfter - {Place}) |- Expr : Type1 (Env, LiveAfter) |- Place : Type2 (Env, LiveAfter) |- Type1 <: Type2 (Env, LiveAfter) permits mut(Place) ----------------------------------------- assignment (Env, LiveAfter) |- Place = Expr : ()Before I dive into how we define “permits”, let’s go back to our example and get an intution for what is going on here. We want to declare an error on this assigment:
let mut counter: u32 = 22_u32; let p: &{shared(counter)} u32 = &counter; counter += 1; // <-- Error println!("{p}"); // <-- p is liveNote that, because of the println! on the next line, p will be in our LiveAfter set. Looking at the type of p, we see that it includes the loan shared(counter). The idea then is that mutating counter is illegal because there is a live loan shared(counter), which implies that counter must be immutable.
Restating that intution:
A set Live of live places permits a loan Loan1 if, for every live place Place in Live, the loans in the type of Place are compatible with Loan1.
Written more formally:
∀ Place ∈ Live { (Env, Live) |- Place : Type ∀ Loan2 ∈ Loans(Type) { Compatible(Loan1, Loan2) } } ----------------------------------------- (Env, Live) permits Loan1This definition makes use of two helper functions:
- Loans(Type) – the set of loans that appear in the type
- Compatible(Loan1, Loan2) – defines if two loans are compatible. Two shared loans are always compatible. A mutable loan is only compatible with another loan if the places are disjoint.
The goal of this post was to give a high-level intution. I wrote it from memory, so I’ve probably overlooked a thing or two. In follow-up posts though I want to go deeper into how the system I’ve been playing with works and what new things it can support. Some high-level examples:
- How to define subtyping, and in particular the role of liveness in subtyping
- Important borrow patterns that we use today and how they work in the new system
- Interior references that point at data owned by other struct fields and how it can be supported
-
If this is not obvious to you, don’t worry, it wasn’t obvious to me either. It turns out that using liveness in the rules is the key to making them simple. I’ll try to write a follow-up about the alternatives I explored and why they don’t work later on. ↩︎
Mozilla Thunderbird: Towards Thunderbird for Android – K-9 Mail 6.800 Simplifies Adding Email Accounts

We’re happy to announce the release of K-9 Mail 6.800. The main goal of this version is to make it easier for you to add your email accounts to the app.
With another item crossed off the list, this brings us one step closer towards Thunderbird for Android.
New account setupSetting up an email account in K-9 Mail is something many new users have struggled with in the past. That’s mainly because automatic setup was only supported for a handful of large email providers. If you had an email account with another email provider, you had to manually enter the incoming and outgoing server settings. But finding the correct server settings can be challenging.
So we set out to improve the setup experience. Since this part of the app was quite old and had a couple of other problems, we used this opportunity to rewrite the whole account setup component. This turned out to be more work than originally anticipated. But we’re quite happy with the result.
Let’s have a brief look at the steps involved in setting up a new account.
1. Enter email addressTo get the process started, all you have to do is enter the email address of the account you want to set up in K-9 Mail.
 2. Provide login credentials
2. Provide login credentials
After tapping the Next button, the app will use Thunderbird’s Autoconfig mechanism to try to find the appropriate incoming and outgoing server settings. Then you’ll be asked to provide a password or use the web login flow, depending on the email provider.
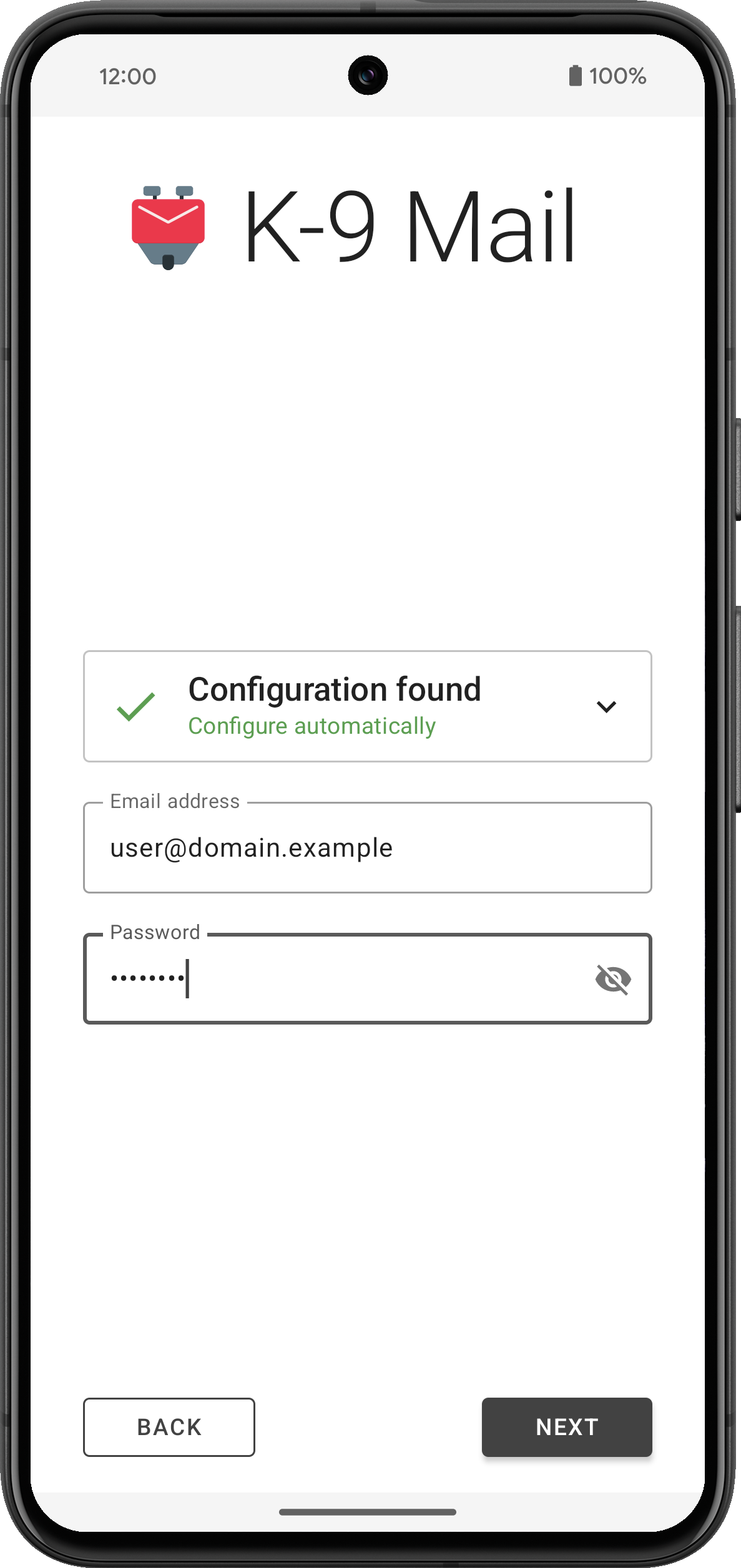
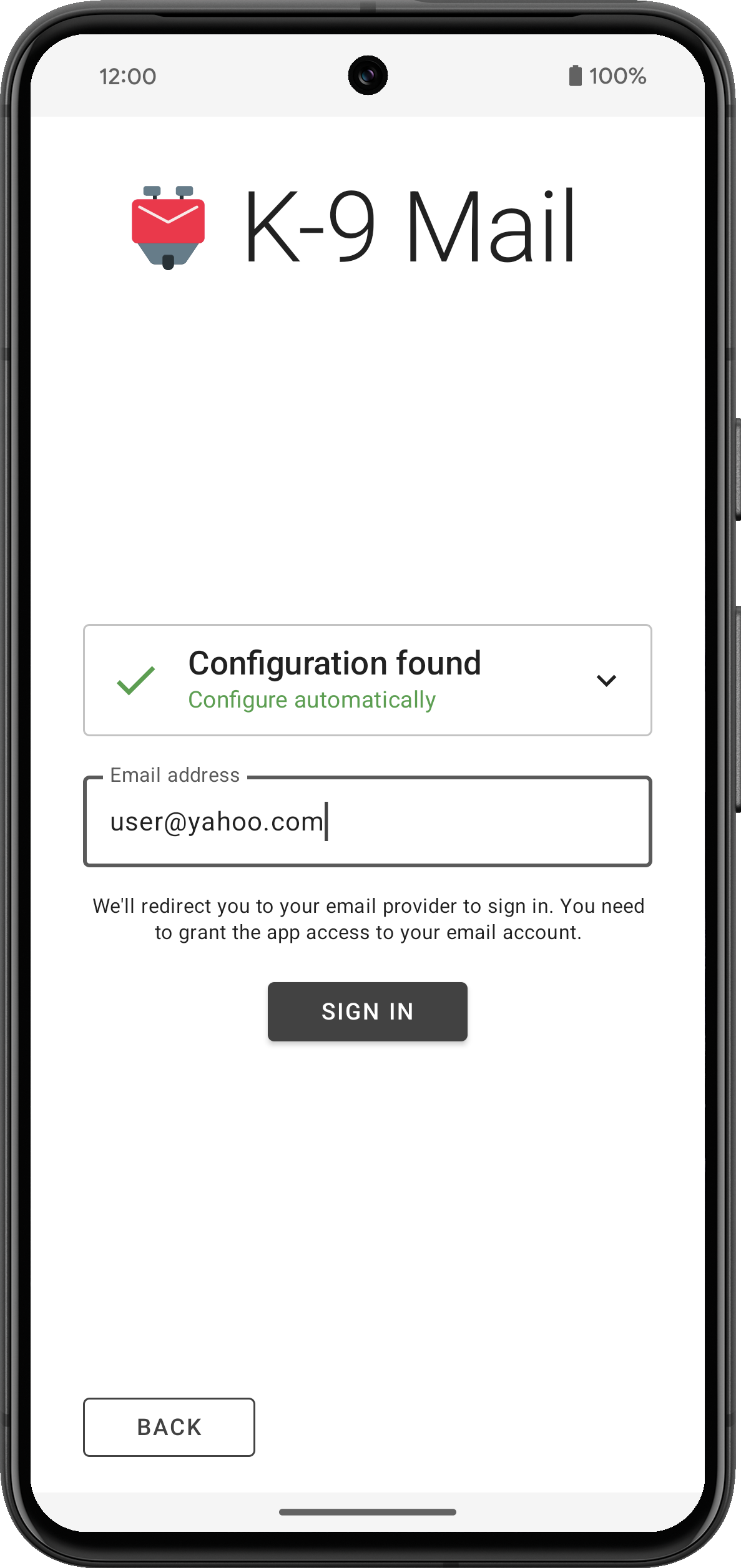
The app will then try to log in to the incoming and outgoing server using the provided credentials.
3. Provide some basic information about the accountIf your login credentials check out, you’ll be asked to provide your name for outgoing messages. For all the other inputs you can go with the defaults. All settings can be changed later, once an account has been set up.
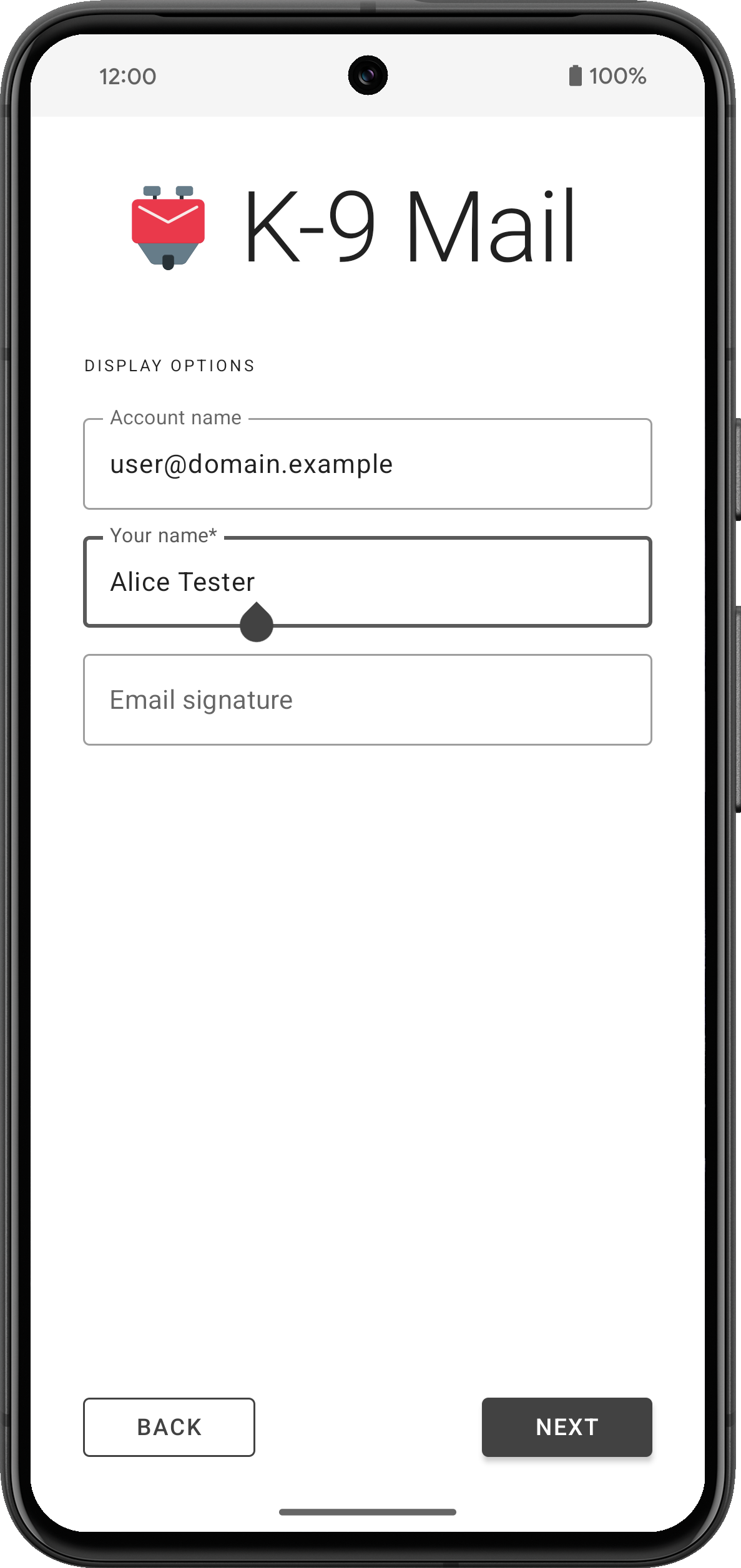
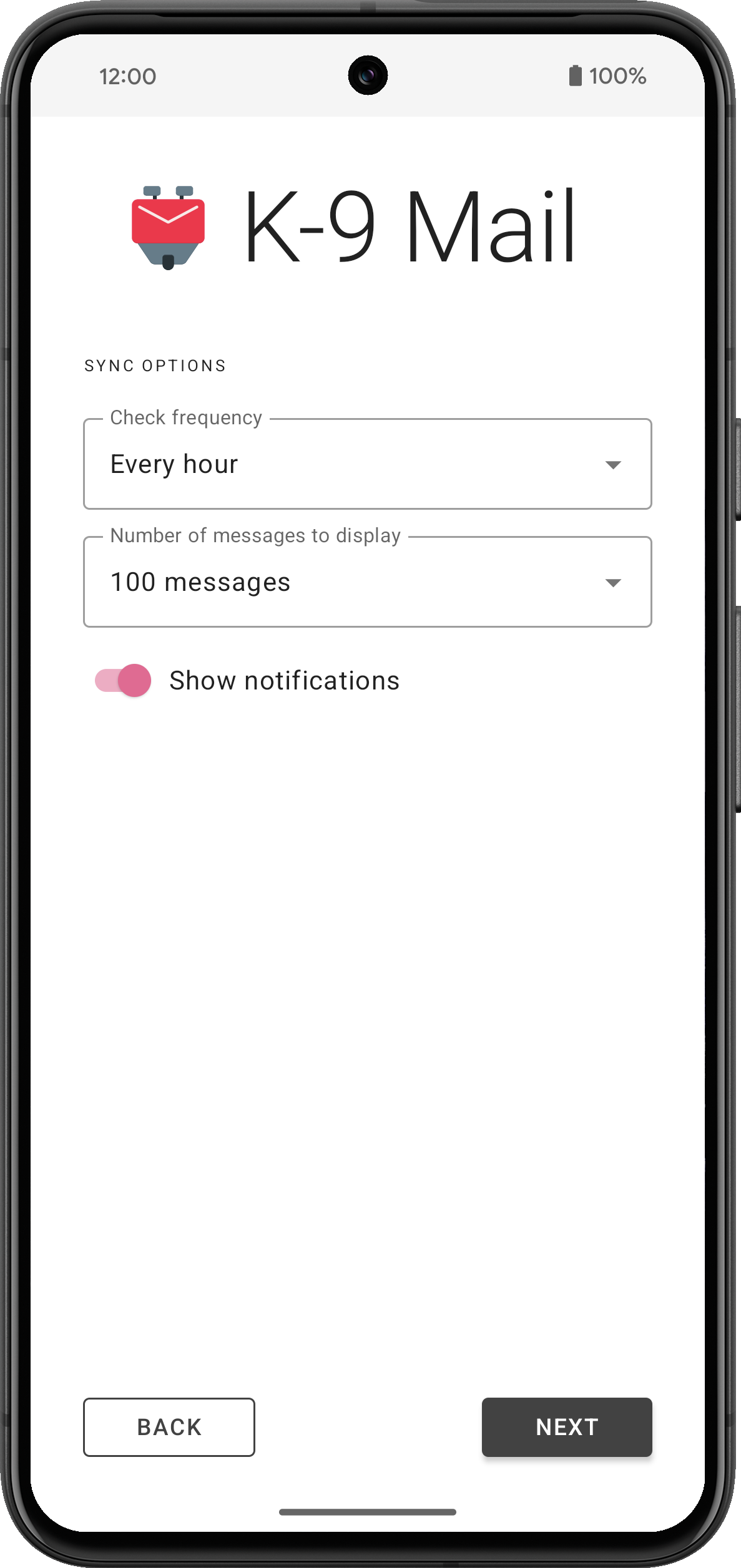
If everything goes well, that’s all it takes to set up an account.
Of course there’s still cases where the app won’t be able to automatically find a configuration and the user will be asked to manually provide the incoming and outgoing server settings. But we’ll be working with email providers to hopefully reduce the number of times this happens.
What else is new?While the account setup rewrite was our main development focus, we’ve also made a couple of smaller changes and bug fixes. You can find a list of the most notable ones below.
Improvements and behavior changes- Made it harder to accidentally trigger swipe actions in the message list screen
- IMAP: Added support for sending the ID command (that is required by some email providers)
- Improved screen reader experience in various places
- Improved display of some HTML messages
- Changed background color in message view and compose screens when using dark theme
- Adding to contacts should now allow you again to add the email address to an existing contact
- Added image handling within the context menu for hyperlinks
- A URI pasted when composing a message will now be surrounded by angle brackets
- Don’t use nickname as display name when auto-completing recipient using the nickname
- Changed compose icon in the message list widget to match the icon inside the app
- Don’t attempt to open file: URIs in an email; tapping such a link will now copy the URL to the clipboard instead
- Added option to return to the message list after marking a message as unread in the message view
- Combined settings “Return to list after delete” and “Show next message after delete” into “After deleting or moving a message”
- Moved “Show only subscribed folders” setting to “Folders” section
- Added copy action to recipient dropdown in compose screen (to work around missing drag & drop functionality)
- Simplified the app icon so it can be a vector drawable
- Added support for the IMAP MOVE extension
- Fixed bug where account name wasn’t displayed in the message view when it should
- Fixed bugs with importing and exporting identities
- The app will no longer ask to save a draft when no changes have been made to an existing draft message
- Fixed bug where “Cannot connect to crypto provider” was displayed when the problem wasn’t the crypto provider
- Fixed a crash caused by an interaction with OpenKeychain 6.0.0
- Fixed inconsistent behavior when replying to messages
- Fixed display issue with recipients in message view screen
- Fixed display issues when rendering a message/rfc822 inline part
- Fixed display issue when removing an account
- Fixed notification sounds on WearOS devices
- Fixed the app so it runs on devices that don’t support home screen widgets
- Removed Hebrew and Korean translations because of how incomplete they were; volunteer translators welcome!
- A fresh app install on Android 14 will be missing the “alarms & reminders” permission required for Push to work. Please allow setting alarms and reminders in Android’s app settings under Alarms & reminders.
- Some software keyboards automatically capitalize words when entering the email address in the first account setup screen.
- When a password containing line breaks is pasted during account setup, these line breaks are neither ignored nor flagged as an error. This will most likely lead to an authentication error when checking server settings.
Version 6.800 has started gradually rolling out. As always, you can get it on the following platforms:
GitHub | F-Droid | Play Store
(Note that the release will gradually roll out on the Google Play Store, and should appear shortly on F-Droid, so please be patient if it doesn’t automatically update.)
The post Towards Thunderbird for Android – K-9 Mail 6.800 Simplifies Adding Email Accounts appeared first on The Thunderbird Blog.
Mozilla Addons Blog: Developer Spotlight: YouTube Search Fixer
Like a lot of us during the pandemic lockdown, Shubham Bose found himself consuming more YouTube content than ever before. That’s when he started to notice all the unwanted oddities appearing in his YouTube search results — irrelevant suggested videos, shorts, playlists, etc. Shubham wanted a cleaner, more focused search experience, so he decided to do something about it. He built YouTube Search Fixer. The extension streamlines YouTube search results in a slew of customizable ways, like removing “For you,” “People also search for,” “Related to your search,” and so on. You can also remove entire types of content like shorts, live streams, auto-generated mixes, and more.
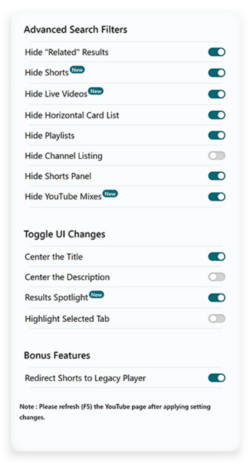
The extension makes it easy to customize YouTube to suit you.
Early versions of the extension were less customizable and removed most types of suggested search results by default, but over time Shubham learned that different users want different things in their search results. “I realized the line between ‘helpful’ and ‘distracting’ is very subjective,” explains Shubham. “What one person finds useful, another might not. Ultimately, it’s up to the user to decide what works best for them. That’s why I decided to give users granular control using an Options page. Now people can go about hiding elements they find distracting while keeping those they deem helpful. It’s all about striking that personal balance.”
Despite YouTube Search Fixer’s current wealth of customization options (a cool new feature automatically redirects Shorts to their normal length versions), Shubham plans to expand his extension’s feature set. He’s considering keyword highlighting and denylist options, which would give users extreme control over search filtering.
More than solving what he felt was a problem with YouTube’s default search results, Shubham was motivated to build his extension as a “way of giving back to a community I deeply appreciate… I’ve used Firefox since I was in high school. Like countless others, I’ve benefited greatly from the ever helpful MDN Web Docs and the incredible add-ons ecosystem Mozilla hosts and helps thrive. They offer nice developer tools and cultivate a helpful and welcoming community. So making this was my tiny way of giving back and saying ‘thank you’.”

When he’s not writing extensions that improve the world’s most popular video streaming site, Shubham enjoys photographing his home garden in Lucknow, India. “It isn’t just a hobby,” he explains. “Experimenting with light, composition and color has helped me focus on visual aesthetics (in software development). Now, I actively pay attention to little details when I create visually appealing and user-friendly interfaces.”
Do you have an intriguing extension development story? Do tell! Maybe your story should appear on this blog. Contact us at amo-featured [at] mozilla [dot] org and let us know a bit about your extension development journey.
The post Developer Spotlight: YouTube Search Fixer appeared first on Mozilla Add-ons Community Blog.
Mozilla Thunderbird: Thunderbird Monthly Development Digest: February 2024

Hello Thunderbird Community! I can’t believe it’s already the end of February. Time goes by very fast and it seems that there’s never enough time to do all the things that you set your mind to. Nonetheless, it’s that time of the month again for a juicy and hopefully interesting Thunderbird Development Digest.
If this is your first time reading our monthly Dev Digest, these are short posts to give our community visibility into features and updates being planned for Thunderbird, as well as progress reports on work that’s in the early stages of development.
Let’s jump right into it, because there’s a lot to get excited about!
Rust and ExchangeThings are moving steadily on this front. Maybe not as fast as we would like, but we’re handling a complicated implementation and we’re adding a new protocol for the first time in more than a decade, so some friction is to be expected.
Nonetheless, you can start following the progress in our Thundercell repository. We’re using this repo to temporarily “park” crates and other libraries we’re aiming to vendor inside Thunderbird.
We’re aiming at reaching an alpha state where we can land in Thunderbird later next month and start asking for user feedback on Daily.
Mozilla Account + Thunderbird Sync <figcaption class="wp-element-caption">Illustration by Alessandro Castellani</figcaption>
<figcaption class="wp-element-caption">Illustration by Alessandro Castellani</figcaption>
Things are moving forward on this front as well. We’re currently in the process of setting up our own SyncServer and TokenStorage in order to allow users to log in with their Mozilla Account but sync the Thunderbird data in an independent location from the Firefox data. This gives us an extra layer of security as it will prevent an app from accessing the other app’s data and vice versa.
In case you didn’t know, you can already use a Mozilla account and Sync on Daily, but this only works with a staging server and you’ll need an alternate Mozilla account for testing. There are a couple of known bugs but overall things seem to be working properly. Once we switch to our storage server, we will expose this feature more and enable it on Beta for everyone to test.
Oh, Snap!Our continuous efforts to own our packages and distribution methods is moving forward with the internal creation of a Snap package. (For background, last year we took ownership of the Thunderbird Flatpak.)
We’re currently internally testing the Beta and things seem to work accordingly. We will announce it publicly when it’s available from the Snap Store, with the objective of offering both Stable and Beta channels.
We’re exploring the possibility of also offering a Daily channel, but that’s a bit more complicated and we will need more time to make sure it’s doable and automated, so stay tuned.
As usual, if you want to see things as they land you can always check the pushlog and try running daily, which would be immensely helpful for catching bugs early.
See ya next month,
Alessandro Castellani (he, him)
Director of Product Engineering
If you’re interested in joining the technical discussion around Thunderbird development, consider joining one or several of our mailing list groups here.
The post Thunderbird Monthly Development Digest: February 2024 appeared first on The Thunderbird Blog.
The Rust Programming Language Blog: Clippy: Deprecating `feature = "cargo-clippy"`
Since Clippy v0.0.97 and before it was shipped with rustup, Clippy implicitly added a feature = "cargo-clippy" config1 when linting your code with cargo clippy.
Back in the day (2016) this was necessary to allow, warn or deny Clippy lints using attributes:
#[cfg_attr(feature = "cargo-clippy", allow(clippy_lint_name))]Doing this hasn't been necessary for a long time. Today, Clippy users will set lint levels with tool lint attributes using the clippy:: prefix:
#[allow(clippy::lint_name)]The implicit feature = "cargo-clippy" has only been kept for backwards compatibility, but will be deprecated in upcoming nightlies and later in 1.78.0.
AlternativeAs there is a rare use case for conditional compilation depending on Clippy, we will provide an alternative. So in the future (1.78.0) you will be able to use:
#[cfg(clippy)] TransitioningShould you only use stable toolchains, you can wait with the transition until Rust 1.78.0 (2024-05-02) is released.
Should you have instances of feature = "cargo-clippy" in your code base, you will see a warning from the new Clippy lint clippy::deprecated_clippy_cfg_attr available in the latest nightly Clippy. This lint can automatically fix your code. So if you should see this lint triggering, just run:
cargo clippy --fix -- -Aclippy::all -Wclippy::deprecated_clippy_cfg_attrThis will fix all instances in your code.
In addition, check your .cargo/config file for:
[target.'cfg(feature = "cargo-clippy")'] rustflags = ["-Aclippy::..."]If you have this config, you will have to update it yourself, by either changing it to cfg(clippy) or taking this opportunity to transition to setting lint levels in Cargo.toml directly.
Motivation for DeprecationCurrently, there's a call for testing, in order to stabilize checking conditional compilation at compile time, aka cargo check -Zcheck-cfg. If we were to keep the feature = "cargo-clippy" config, users would start seeing a lot of warnings on their feature = "cargo-clippy" conditions. To work around this, they would either need to allow the lint or have to add a dummy feature to their Cargo.toml in order to silence those warnings:
[features] cargo-clippy = []We didn't think this would be user friendly, and decided that instead we want to deprecate the implicit feature = "cargo-clippy" config and replace it with the clippy config.
-
It's likely that you didn't even know that Clippy implicitly sets this config (which was not a Cargo feature). This is intentional, as we stopped advertising and documenting this a long time ago. ↩
The Servo Blog: This month in Servo: gamepad support, font fallback, Space Jam, and more!
 <figcaption>Font fallback now works for Chinese, Japanese, and Korean.</figcaption>
<figcaption>Font fallback now works for Chinese, Japanese, and Korean.</figcaption>
A couple of weeks ago, Servo surpassed its legacy layout engine in a core set of CSS2 test suites (84.2% vs 82.8% in legacy), but now we’ve surpassed legacy in the whole CSS test suite (63.6% vs 63.5%) as well! More on how we got there in a bit, but first let’s talk about new API support:
- as of 2024-02-07, you can safely console.log() symbols and large arrays (@syvb, #31241, #31267)
- as of 2024-02-07, we support CanvasRenderingContext2D.reset() (@syvb, #31258)
- as of 2024-02-08, we support navigator.hardwareConcurrency (@syvb, #31268)
- as of 2024-02-11, you can look up shorthands like ‘margin’ in getComputedStyle() (@sebsebmc, #31277)
- as of 2024-02-15, we accept SVG with the image/svg+xml mime type (@KiChjang, #31318)
- as of 2024-02-20, we support non-XR game controllers with the Gamepad API (@msub2, #31200)
- as of 2024-02-23, we have basic support for ‘text-transform’ (@mrobinson, @atbrakhi, #31396)
— except ‘full-width’, ‘full-size-kana’, grapheme clusters, and language-specific transforms
As of 2024-02-12, we have basic support for font fallback (@mrobinson, #31254)! This is especially important for pages that mix text from different languages. More work is needed to support shaping across element boundaries and shaping complex scripts like Arabic, but the current version should be enough for Chinese, Japanese, and Korean. If you encounter text that still fails to display, be sure to check your installed fonts against the page styles and Servo’s default font lists (Windows, macOS, Linux).
 <figcaption>
<figcaption>
Space Jam (1996) now has correct layout with --pref layout.tables.enabled.
</figcaption>As of 2024-02-24, layout now runs in the script thread, rather than in a dedicated layout thread (@mrobinson, @jdm, #31346), though it can still spawn worker threads to parallelise layout work. Since the web platform almost always requires layout to run synchronously with script, this should allow us to make layout simpler and more reliable without regressing performance.
Our experimental tables support (--pref layout.tables.enabled) has vastly improved:
- as of 2024-01-26, we compute table column widths (@mrobinson, @Loiroriol, #31165)
- as of 2024-01-30, we support the <table cellpadding> attribute (@Loirooriol, #31201)
- as of 2024-02-11, we support ‘vertical-align’ in table cells (@mrobinson, @Loirooriol, #31246)
- as of 2024-02-14, we support ‘border-spacing’ on tables (@mrobinson, @Loirooriol, #31166, #31337)
- as of 2024-02-21, we support rows, columns, and row/column groups (@mrobinson, @Loirooriol, #31341)
Together with inline layout for <div align> and <center> (@Loirooriol, #31388) landing in 2024-02-24, we now render the classic Space Jam website correctly when tables are enabled!
As of 2024-02-24, we support videos with autoplay (@jdm, #31412), and windows containing videos no longer crash when closed (@jdm, #31413).
Many layout and CSS bugs have also been fixed:
- as of 2024-01-28, correct rounding of clientLeft, clientTop, clientWidth, and clientHeight (@mrobinson, #31187)
- as of 2024-01-30, correct cache invalidation of client{Left,Top,Width,Height} after reflow (@Loirooriol, #31210, #31219)
- as of 2024-02-03, correct width and height for preloaded Image objects (@syvb, #31253)
- as of 2024-02-07, correct [...spreading] and indexing[0] of style objects (@Loirooriol, #31299)
- as of 2024-02-09, correct border widths in fragmented inlines (@mrobinson, #31292)
- as of 2024-02-11, correct UA styles for <hr> (@sebsebmc, #31297)
- as of 2024-02-24, correct positioning of absolutes with ‘inset: auto’ (@mrobinson, #31418)
We’ve landed a few embedding improvements:
- we’ve removed several mandatory WindowMethods relating to OpenGL video playback (@mrobinson, #31209)
- we’ve removed webrender_surfman, and WebrenderSurfman is now in gfx as RenderingContext (@mrobinson, #31184)
We’ve finished migrating our DOM bindings to use typed arrays where possible (@Taym95, #31145, #31164, #31167, #31189, #31202, #31317, #31325), as part of an effort to reduce our unsafe code surface (#30889, #30862).
WebRender and Stylo are two major components of Servo that have been adopted by Firefox, making Servo’s versions of them a downstream fork. To make these forks easier to update, we’ve split WebRender and Stylo out of our main repo (@mrobinson, @delan, #31212, #31351, #31349, #31358, #31363, #31365, #31408, #31387, #31411, #31350).
We’ve fixed one of the blockers for building Servo with clang 16 (@mrobinson, #31306), but a blocker for clang 15 still remains. See #31059 for more details, including how to build Servo against clang 14.
We’ve also made some other dev changes:
- we’ve removed the unmaintained libsimpleservo C API (@mrobinson, #31172), though we’re open to adding a new C API someday
- we’ve upgraded surfman such that it no longer depends on winit (@mrobinson, #31224)
- we’ve added support for building Servo on Asahi Linux (@arrynfr, #31207)
- we’ve fixed problems building Servo on Debian (@mrobinson, @atbrakhi, #31281, #31276) and NixOS (@syvb, #31231)
- we’ve fixed failures when starting multiple CI try jobs at once (@mrobinson, #31347)
- we’ve made several improvements to mach try for starting CI try jobs (@sagudev, @mrobinson, #31141, #31290)
Rakhi Sharma will speak about Servo’s achievements at Open Source Summit North America on 16 April 2024 at 14:15 local time (21:15 UTC).
In the meantime, check out Rakhi’s recent talk Embedding Servo in Rust projects, which she gave at FOSDEM 2024 on 3 February 2024. Here you’ll learn about the state of the art around embedding Servo and Stylo, including a walkthrough of our example browser servoshell, our ongoing effort to integrate Servo with Tauri, and a sneak peek into how Stylo might someday be usable with Dioxus:
Embedding Servo in Rust projects by Rakhi Sharma at FOSDEM 2024
The Rust Programming Language Blog: Updated baseline standards for Windows targets
The minimum requirements for Tier 1 toolchains targeting Windows will increase with the 1.78 release (scheduled for May 02, 2024). Windows 10 will now be the minimum supported version for the *-pc-windows-* targets. These requirements apply both to the Rust toolchain itself and to binaries produced by Rust.
Two new targets have been added with Windows 7 as their baseline: x86_64-win7-windows-msvc and i686-win7-windows-msvc. They are starting as Tier 3 targets, meaning that the Rust codebase has support for them but we don't build or test them automatically. Once these targets reach Tier 2 status, they will be available to use via rustup.
Affected targets- x86_64-pc-windows-msvc
- i686-pc-windows-msvc
- x86_64-pc-windows-gnu
- i686-pc-windows-gnu
- x86_64-pc-windows-gnullvm
- i686-pc-windows-gnullvm
Prior to now, Rust had Tier 1 support for Windows 7, 8, and 8.1 but these targets no longer meet our requirements. In particular, these targets could no longer be tested in CI which is required by the Target Tier Policy and are not supported by their vendor.
The Talospace Project: Firefox 123 on POWER
Patrick Cloke: Joining the Matrix Spec Core Team
I was recently invited to join the Matrix “Spec Core Team”, the group who steward the Matrix protocol, from their own documentation:
The contents and direction of the Matrix Spec is governed by the Spec Core Team; a set of experts from across the whole Matrix community, representing all aspects of the Matrix ecosystem. The Spec Core Team acts as a subcommittee of the Foundation.This was the announced a couple of weeks ago and I’m just starting to get my feet wet! You can see an interview between myself, Tulir (another new member of the Spec Core Team), and Matthew (the Spec Core Team lead) in today’s This Week in Matrix. We cover a range of topics including Thunderbird (and Instantbird), some improvements I hope to make and more.
Patrick Cloke: Synapse URL Previews
Matrix includes the ability for a client to request that the server generate a “preview” for a URL. The client provides a URL to the server which returns Open Graph data as a JSON response. This leaks any URLs detected in the message content to the server, but protects the end user’s IP address, etc. from the URL being previewed. [1] (Note that clients generally disable URL previews for encrypted rooms, but it can be enabled.)
ImprovementsSynapse implements the URL preview endpoint, but it was a bit neglected. I was one of the few main developers running with URL previews enabled and sunk a bit of time into improving URL previews for my on sake. Some highlights of the improvements made include (in addition to lots and lots of refactoring):
- Support oEmbed for URL previews: #7920, #10714, #10759, #10814, #10819, #10822, #11065, #11669 (combine with HTML results), #14089, #14781.
- Reduction of 500 errors: #8883 (empty media), #9333 (unable to parse), #11061 (oEmbed errors).
- Improved support for document encodings: #9164, #9333, #11077, #11089.
- Support previewing XML documents (#11196) and data: URIs (#11767).
- Return partial information if images or oEmbed can’t be fetched: #12950, #15092.
- Skipping empty Open Graph (og) or meta tags: #12951.
- Support previewing from Twitter card information: #13056.
- Fallback to favicon if no images found: #12951.
- Ignore navgiation tags: #12951.
- Document how Synapse generates URL previews: #10753, #13261.
I also helped review many changes by others:
- Improved support for encodings: #10410.
- Safer content-type support: #11936.
- Attempts to fix Twitter previews: #11985.
- Remove useless elements from previews: #12887.
- Avoid crashes due to unbounded recursion: GHSA-22p3-qrh9-cx32.
And also fixed some security issues:
- Apply url_preview_url_blacklist to oEmbed and pre-cached images: #15601.
Overall, there was an improved result (from my point of view). A summary of some of the improvements. I tested 26 URLs (based on ones that had previously been reported or found to give issues). See the table below for testing at a few versions. The error reason was also broken out into whether JavaScript was required or some other error occurred. [2]
Version Release date Successful preview JavaScript required error Found image & description? 1.0.0 2019-06-11 15 4 14 1.12.0 2020-03-23 18 4 17 1.24.0 2020-12-09 20 1 16 1.36.0 2021-06-15 20 1 16 1.48.0 2021-11-30 20 1 11 1.60.0 2022-05-31 21 0 21 1.72.0 2022-11-22 22 0 21 1.84.0 2023-05-23 22 0 21 Future improvementsI am no longer working on Synapse, but some of the ideas I had for additional improvements included:
- Use BeautifulSoup instead of a custom parser to handle some edge cases in HTML documents better (WIP @ clokep/bs4).
- Always request both oEmbed and HTML (WIP @ clokep/oembed-and-html).
- Structured data support (JSON-LD, Microdata, RDFa) (#11540).
- Some minimal JavaScript support (#14118).
- Fixing any of the other issues with particular URLs (see this GitHub search).
- Thumbnailing of SVG images (which sites tend to use for favicons) (#1309).
There’s also a ton more that could be done here if you wanted, e.g. handling more data types (text and PDF are the ones I have frequently come across that would be helpful to preview). I’m sure there are also many other URLs that don’t work right now for some reason. Hopefully the URL preview code continues to improve!
[1]See some ancient documentation on the tradeoffs and design of URL previews. MSC4095 was recently written to bundle the URL preview information into evens. [2]This was done by instantiating different Synapse versions via Docker and asking them to preview URLs. (See the code.) This is not a super realistic test since it assumes that URLs are static over time. In particular some sites (e.g. Twitter) like to change what they allow you to access without being authenticated.The Rust Programming Language Blog: Rust participates in Google Summer of Code 2024
We're writing this blog post to announce that the Rust Project will be participating in Google Summer of Code (GSoC) 2024. If you're not eligible or interested in participating in GSoC, then most of this post likely isn't relevant to you; if you are, this should contain some useful information and links.
Google Summer of Code (GSoC) is an annual global program organized by Google that aims to bring new contributors to the world of open-source. The program pairs organizations (such as the Rust Project) with contributors (usually students), with the goal of helping the participants make meaningful open-source contributions under the guidance of experienced mentors.
As of today, the organizations that have been accepted into the program have been announced by Google. The GSoC applicants now have several weeks to send project proposals to organizations that appeal to them. If their project proposal is accepted, they will embark on a 12-week journey during which they will try to complete their proposed project under the guidance of an assigned mentor.
We have prepared a list of project ideas that can serve as inspiration for potential GSoC contributors that would like to send a project proposal to the Rust organization. However, applicants can also come up with their own project ideas. You can discuss project ideas or try to find mentors in the #gsoc Zulip stream. We have also prepared a proposal guide that should help you with preparing your project proposals.
You can start discussing the project ideas with Rust Project maintainers immediately. The project proposal application period starts on March 18, 2024, and ends on April 2, 2024 at 18:00 UTC. Take note of that deadline, as there will be no extensions!
If you are interested in contributing to the Rust Project, we encourage you to check out our project idea list and send us a GSoC project proposal! Of course, you are also free to discuss these projects and/or try to move them forward even if you do not intend to (or cannot) participate in GSoC. We welcome all contributors to Rust, as there is always enough work to do.
This is the first time that the Rust Project is participating in GSoC, so we are quite excited about it. We hope that participants in the program can improve their skills, but also would love for this to bring new contributors to the Project and increase the awareness of Rust in general. We will publish another blog post later this year with more information about our participation in the program.
Mozilla Performance Blog: Web Performance @ FOSDEM 2024
FOSDEM (Free and Open Source Software Developers’ European Meeting) is one of the largest gatherings of open-source enthusiasts, developers, and advocates worldwide. Each year there are many focused developer rooms (devrooms), managed by volunteers, and this year’s edition on 3-4 February saw the return of the Web Performance devroom managed by Peter Hedenskog from Wikimedia and myself (Dave Hunt) from Mozilla. Thanks to so many great talk proposals (we easily could have filled a full day), we were able to assemble a fantastic schedule, and at times the room was full, with as many people standing outside hoping to get in!
Dive into the talksThanks to the FOSDEM organisers and preparation from our speakers, we successfully managed to squeeze nine talks into the morning with a tight turnaround time. Here’s a rundown of the sessions:
1. The importance of Web Performance to Information EquityBas Schouten kicked off the morning with his informative talk on the vital role web performance plays on ensuring equal access to information and services for those with slower devices.
2. Let’s build a RUM system with open source toolsNext up we had Tsvetan Stoychev share what he’s learned working on Basic RUM – an open source real user monitoring system.
3. Better than loading fast… is loading instantly!At this point the room was at capacity, with at least as many people waiting outside! Next, Barry Pollard gave shared details on how to score near-perfect Core Web Vitals in his talk on pre-fetching and pre-rendering.
4. Keyboard InteractionsPatricija Cerkaite followed with her talk on how she helped to improve measuring keyboard interactions, and how this influenced Interaction to Next Paint, leading to a better experience for Input Method Editors (IME).
5. Web Performance at Mozilla and WikimediaMidway through the morning, Peter Hedenskog & myself shared some insights into how Wikimedia and Mozilla measure performance in our talk. Peter shared a some public dashboards, and I ran through a recent example of a performance regression affecting our page load tests.
6. Understanding how the web browser works, or tracing your way out of (performance) problemsWe handed the spotlight over to Alexander Timin for his talk on event tracing and browser engineering based on his experience working on the Chromium project.
7. Fast JavaScript with Data-Oriented DesignThe morning continued to go from strength to strength, with Markus Stange demonstrating in his talk how to iterate and optimise a small example project and showing how easy it is to use the Firefox Profiler.
8. From Google AdSense to FOSS: Lightning-fast privacy-friendly bannersAs we got closer to lunch, Tim Vereecke teased us with hamburger banner ads in his talk on replacing Google AdSense with open source alternative Revive Adserver to address privacy and performance concerns.
9. Insights from the RUM ArchiveFor our final session of the morning, Robin Marx introduced us to the RUM Archive, shared some insights and challenges with the data, and discussed the part real user monitoring plays alongside other performance analysis.
Beyond the devroomIt was great to see that the topic of web performance wasn’t limited to our devroom, with talks such as Debugging HTTP/3 upload speed in Firefox in the Mozilla devroom, Web Performance: Leveraging Qwik to Meet Google’s Core Web Vitals in the JavaScript devroom, and Firefox power profiling: a powerful visualization of web sustainability in the main track.
AcknowledgementsI would like to thank all the amazing FOSDEM volunteers for supporting the event. Thank you to our wonderful speakers and everyone who submitted a proposal for providing us with such an excellent schedule. Thank you to Peter Hedenskog for bringing his devroom management experience to the organisation and facilitation of the devroom. Thank you to Andrej Glavic, Julien Wajsberg, and Nazım Can Altınova for their help managing the room and ensuring everything ran smoothly. See you next year!