
The Servo Blog: January in Servo: preloads, better forms, details styling, and more!
Servo 0.0.5 is here, bringing with it lots of improvements in web platform features. Some highlights:
- <link rel=preload> (@TimvdLippe, @jdm, #40059)
- <style blocking> and <link blocking> (@TimvdLippe, #42096)
- <img align> (@mrobinson, #42220)
- <select disabled> (@simonwuelker, #42036)
- OGG files can now be played in <audio> (@jdm, #41789)
- ‘cursor-color’ (@mrobinson, #41976)
- ‘content: <image>’ works on all elements (@andreubotella, #41480)
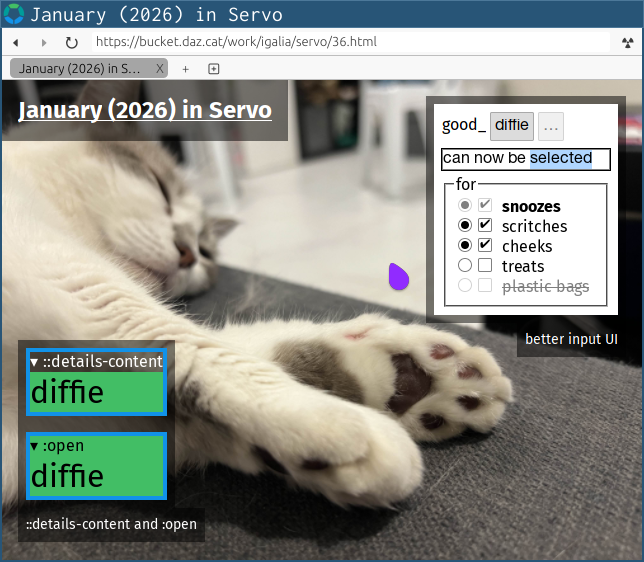
- ‘::details-content’ on <details> (@lukewarlow, #42107)
- ‘:open’ on <details> (@lukewarlow, #42195)
- ‘:active’ on <input type=button> (@mrobinson, #42095)
- Origin API (@WaterWhisperer, #41712)
- MouseEvent.detail (@mrobinson, #41833)
- Request.keepalive (@TimvdLippe, @WaterWhisperer, #41457, #41811)
- Cyclic imports, import attributes, and JSON modules (@Gae24, #41779)
- navigator.sendBeacon() is enabled by default (@TimvdLippe, #41694)
- https_proxy, HTTPS_PROXY, and NO_PROXY (@Narfinger, #41689)
- ML-KEM, ML-DSA, and AES-OCB in Crypto (@kkoyung, #41604, #41617, #41615, #41627, #41628, #41647, #41659, #41676, #41791, #41822, #41813, #41829)
 Web APIs
Web APIs
Servo now plays OGG media inside <audio> elements (@jdm, #41789)! We disabled this feature many years ago due to bugs in GStreamer, our media playback engine, but those bugs have since been fixed.
We now support non-px sizes for width and height attributes in <svg> elements (@rodio, #40761).
Inactive documents will now correctly reject fullscreen mode changes (@stevennovaryo, #42068).
We’ve enabled support for the navigator.sendBeacon() by default (@TimvdLippe, #41694); the dom_navigator_sendbeacon_enabled preference has been removed. As part of this work, we implemented the keepalive feature of the Request API (@TimvdLippe, @WaterWhisperer, #41457, #41811).
That’s not all for network-related improvements! Quota errors from the fetchLater() API provide more details (@TimvdLippe, #41665), and fetch response body promises now reject when invalid gzip content is encountered (@arayaryoma, #39438). Meanwhile, EventSource connections will no longer endlessly reconnect for permanent failures (@WaterWhisperer, #41651, #42137), and now use the correct ‘Last-Event-Id’ header when reconnecting (@WaterWhisperer, #42103). Finally, Servo will create PerformanceResourceTiming entries for requests that returned unsuccessful responses (@bellau, #41804).
There has been lots of work related to navigating pages and loading iframes. We process URL fragments more consistently when navigating via window.location (@TimvdLippe, #41805, #41834), and allow evaluating javascript: URLs when a document’s domain has been modified (@jdm, #41969). XML documents loaded in an <iframe> no longer inherit their encoding from the parent document (@simonwuelker, #41637).
We’re also made it possible to use blob: URLs from inside ‘about:blank’ and ‘about:srcdoc’ documents (@jdm, #41966, #42104). Finally, constructed documents (e.g. new Document()) now inherit the origin and domain of the document that created them (@TimvdLippe, #41780), and we implemented the new Origin API (@WaterWhisperer, #41712).
Servo’s mixed content protections are steadily increasing. Insecure requests (e.g. HTTP) originating from <iframe> elements can now be upgraded to secure protocols (@WaterWhisperer, #41661), and redirected requests now check the most recent URL when determining if the protocol is secure (@WaterWhisperer, #41832).
<style blocking> and <link blocking> can now be used to block rendering while loading stylesheets that are added dynamically (@TimvdLippe, #42096), and stylesheets loaded when parsing the document will block the document ‘load’ event more consistently (@TimvdLippe, @mrobinson, #41986, #41987, #41988, #41973). We also fire the ‘error’ event if a fetched stylesheet response is invalid (@TimvdLippe, @mrobinson, #42037).
Servo now leads other browsers in support for new Web Cryptography algorithms! This includes full support for ML-KEM (@kkoyung, #41604, #41617, #41615, #41627), ML-DSA (@kkoyung, #41628, #41647, #41659, #41676), and AES-OCB (@kkoyung, #41791, #41822, #41813, #41829), plus improvements to AES-GCM (@kkoyung, #41950). Additionally, the error messages returned by many Crypto APIs are now more detailed (@PaulTreitel, @danilopedraza, #41964, #41468, #41902).
JS module loading received a lot of attention – we’ve improved support for cyclic imports (@Gae24, #41779), import attributes (@Gae24, #42185), and JSON modules (@Gae24, @jdm, #42138).
Additionally, the <link rel=preload> attribute now triggers preload fetch operations that can improve page load speeds (@TimvdLippe, @jdm, #40059).
IndexedDB support continues to make progress, though for now the feature is disabled by default (--pref dom_indexeddb_enabled). This month we gained improvements to connection queues (@gterzian, #41500, #42053) and request granularity (@gterzian, #41933).
We were accidentally persisting SessionStorage data beyond the current session, but this has been corrected (@arihant2math, #41326).
Text input fields have received a lot of love this month. Clicking in an input field will position the cursor accordingly (@mrobinson, @jdm, @Loirooriol, #41906, #41974, #41931), as will clicking past the end of a multiline input (@mrobinson, @Loirooriol, #41909). Selecting text with the mouse in input fields works (@mrobinson, #42049), and double and triple clicks now toggle selections (@mrobinson, #41926). Finally, we fixed a bug causing the input caret to be hidden in <input> elements inside of Shadow DOM content (@stevennovaryo, #42233).
‘cursor-color’ is respected when rendering the input cursor (@mrobinson, #41976), and newlines can no longer be pasted into single line inputs (@mrobinson, #41934). Finally, we fixed a panic when focusing a text field that is disabled (@mrobinson, #42078), as well as panics in APIs like HTMLInputElement.setRangeText() that confused bytes and UTF-8 character indices (@mrobinson, #41588).
We also made time to improve form controls! The default styling of many controls received some care (@mrobinson, #42085), while <input type=button> can now be styled with the ‘:active’ pseudo-class (@mrobinson, #42095). Conversely, disabled <select> elements can no longer be activated (@simonwuelker, #42036).
Mouse events triggered by the embedder are more complete; MouseEvent.detail correctly reports the click count for ‘mouseup’ and ‘mousedown’ events (@mrobinson, #41833), and many other members are now consistent with other mouse events (@mrobinson, #42013).
Performing a pinch zoom on mobile is now reflected in the VisualViewport API (@stevennovaryo, #41754), though for now the feature is disabled by default (--pref dom_visual_viewport_enabled).
We’ve changed the behaviour of Web APIs that use the [Clamp] annotation (such as Blob.slice()). The previous implementation would cast floating point values to their integer equivalents, but the standard requires more specific rounding logic (@Taym95, #41640).
The RGBA8 constant is now available in WebGL 1 rendering contexts; it was previously only available in WebGL 2 contexts (@simonwuelker, #42048).
Fonts were another area of focus this month. Loading web fonts from file: URLs works as expected (@TimvdLippe, #41714), as does using web fonts within Shadow DOM content (@minghuaw, #42151). Each web font request now creates a PerformanceResourceTiming entry (@lumi-me-not, #41784). Servo supports font variations as of November 2025, so as of this month, the FontFace constructor no longer ignores the ‘font-variation-settings’ property (@muse254, #41968).
Cursive scripts now ignore the ‘letter-spacing’ CSS property (@mrobinson, #42165), and we significantly reduced the time and memory required when rendering non-ASCII text (@mrobinson, @Loirooriol, #42105, #42162) and when text nodes share the same font (@mrobinson, #41876).
CSSThere were lots of improvements to block layout algorithms (@Loirooriol, #41492, #41624, #41632, #41655, #41652, #41683). These often affect pages where a block element (such as a <div>) exists within some other layout mode (such as an inline <span>, or a flexbox context), and fixes like these ensure Servo matches the output of other browsers.
Elements with scrollable overflow can be scrolled more consistently, even with CSS transforms applied to them (@stevennovaryo, #41707, #42005).
You can now use ‘content: <image>’ on any element (@andreubotella, #41480). Generated image content used to only work with pseudo-elements, but that restriction no longer applies.
<details> elements can now be styled with the ‘::details-content’ pseudo-element (@lukewarlow, #42107), as well as the ‘:open’ pseudo-class (@lukewarlow, #42195).
CSS styles now inherit correctly through ‘display: contents’ as well as <slot> elements in Shadow DOM content (@longvatrong111, @Loirooriol, @mrobinson, #41855).
‘overflow-clip-margin’ now works correctly when ‘border-radius’ is present (@Loirooriol, #41967).
We fixed bugs involving text inside flexbox elements: they now use consistent baselines for alignment (@lukewarlow, @mrobinson, #42038), and style updates are propagated to the text correctly (@mrobinson, #41951).
<img align> now aligns the image as expected (@mrobinson, #42220).
‘word-break: keep-all’ now prevents line breaks in CJK text (@RichardTjokroutomo, #42088).
We also fixed some bugs involving floats, collapsing margins, and phantom line boxes (@Loirooriol, #41812), which sound much cooler than they actually are.
Finally, we upgraded our Stylo dependency to the latest changes as of January 1 2026 (@Loirooriol, #41916, #41696). Stylo powers our CSS parsing and style resolution engine, and this upgrade improves support for parsing color functions like ‘color-mix()’, and improves our CSS animations and transitions for borders and overflow clipping.
Automation and introspectionLast month Servo gained support for HTTP proxies. We now support HTTPS proxies as well (@Narfinger, #41689), which can be configured with the https_proxy or HTTPS_PROXY environment variables, or the network_https_proxy_uri preference. In addition, the NO_PROXY environment variable or the network_http_no_proxy preference can disable any proxy for particular domains.
Our developer tools integration continues to improve. Worker globals are now categorized correctly in the UI (@atbrakhi, #41929), and the Sources panel is populated for very short documents (@atbrakhi, #41983). Servo will report console messages that were logged before the developer tools are opened (@eerii, @mrobinson, #41895). Finally, we fixed a panic when selecting nodes in the layout inspector that have no style information (@eerii, #41800).
We’re working towards supporting pausing in the JS debugger (@eerii, @atbrakhi, @jdm, #42007), and breakpoints can be toggled through the UI (@eerii, @atbrakhi, #41925, #42154). While the debugger is paused, hovering over JS objects will report the object’s properties for builtin JS classes (@eerii, @atbrakhi, #42186). Stay tuned for more JS debugging updates in next month’s blog post!
Servo’s WebDriver server is also maturing. Evaluating a synchronous script that returns a Promise will wait until that promise settles (@yezhizhen, #41823). ‘touchmove’ events are fired for pointer actions when a button is pressed (@yezhizhen, #41801), and ‘touchcancel’ events are fired for canceled pointer action items (@yezhizhen, #41937). Finally, any pointer actions that would trigger duplicate ‘mousemove’ events are silently discarded (@mrobinson, #42034).
Element Clear commands now test whether the element is interactable (@yezhizhen, #42124). Now a null script execution timeout value will never trigger a timeout (@yezhizhen, #42184), and synthesized ‘pointermove’ events have a consistent pointerId value (@yezhizhen, #41726).
EmbeddingYou can now cross-compile Servo using Windows as the host (@yezhizhen, #41748).
We’ve pinned all git dependencies to specific revisions, to reduce the risk of build failures (@Narfinger, #42029). We intend to eventually forbid git dependencies in Servo libraries, which will help unblock releasing Servo on crates.io.
SiteDataManager now has a new clear_site_data() method to clear all stored data for a particular host (@janvarga, #41618, #41709, #41852).
Our nightly testing UI, servoshell, now respects any customized installation path on Windows (@yezhizhen, #41653). We fixed a crash in the Android app when pausing the application (@NiklasMerz, #41827). Additionally, clicking inside a webview in the desktop app will remove focus from any browser UI (@mrobinson, #42080).
We’ve laid more groundwork towards exposing accessibility tree information from webviews (@delan, @lukewarlow, @alice, #41924). There’s nothing to test yet, but keep an eye on our tracking issue if you want to be notified when nightly builds are ready for testing!
Stability & performanceWe’ve converted many uses of IPC channels in the engine to channels that are more efficient when multiprocess mode is disabled (@Narfinger, @jdm, @sagudev, @mrobinson, #41178, #41071, #41733, #41806, #41380, #41809, #41774, #42032, #42033, #41412). Since multiprocess mode is not yet enabled by default (--multiprocess), this is a significant boost to Servo’s everyday performance.
Servo now sets a socket timeout for HTTP connections (@Narfinger, @mrobinson, #41710). This is controlled by the network_connection_timeout preference, and defaults to 15 seconds.
Each instance of Servo now starts four fewer threads (@Narfinger, #41740). Any network operations that trigger a synchronous UI operation (such as an HTTP authentication prompt) no longer blocks other network tasks from completing (@Narfinger, @jdm, #41965, #41857).
It’s said that one of the hardest problems in computer science is cache invalidation. We improved the memory usage of dynamic inline SVG content by evicting stale SVG tree data from a cache (@TomRCummings, #41675). Meanwhile, we added a new cache to reduce memory usage and improve rendering performance for pages with animating images (@Narfinger, #41956).
Servo’s JS engine now accounts for 2D and 3D canvas-related memory usage when deciding how often to perform garbage collection (@sagudev, #42180). This can reduce the risk of out-of-memory (OOM) errors on pages that create large numbers of short-lived WebGL or WebGPU objects.
To reduce the risk of panics involving the JS engine integration, we’re continuing to use the Rust type system to make certain kinds of dynamic borrow failures impossible (@sagudev, #41692, #41782, #41756, #41808, #41879, #41878, #41955, #41971, #42123). We also continue to identify and forbid code patterns that can trigger rare crashes when garbage collection happens while destroying webviews (@willypuzzle, #41717, #41783, #41911, #41911, #41977, #41984, #42243).
This month also brought fixes for panics in parallel layout (@mrobinson, #42026), WebGPU (@WaterWhisperer, #42050), <link> fetching (@jdm, #42208), Element.attachShadow() (@mrobinson, #42237), text input methods (@mrobinson, #42240), Web Workers when the developer tools are active (@mrobinson, #42159), IndexedDB (@gterzian, #41960), and asynchronous session history updates (@mrobinson, #42238).
Node.compareDocumentPosition() is now more efficient (@webbeef, #42260), and selections in text inputs no longer require a full page layout (@mrobinson, @Loirooriol, #41963).
DonationsThanks again for your generous support! We are now receiving 7007 USD/month (−1.4% over December) in recurring donations. This helps us cover the cost of our speedy CI and benchmarking servers, one of our latest Outreachy interns, and funding maintainer work that helps more people contribute to Servo.
Servo is also on thanks.dev, and already 33 GitHub users (+3 over December) that depend on Servo are sponsoring us there. If you use Servo libraries like url, html5ever, selectors, or cssparser, signing up for thanks.dev could be a good way for you (or your employer) to give back to the community.
We now have sponsorship tiers that allow you or your organisation to donate to the Servo project with public acknowlegement of your support. A big thanks from Servo to our newest Bronze Sponsor: str4d! If you’re interested in this kind of sponsorship, please contact us at join@servo.org.
7007 USD/month 10000Use of donations is decided transparently via the Technical Steering Committee’s public funding request process, and active proposals are tracked in servo/project#187. For more details, head to our Sponsorship page.
Conference talks and blogsThere were two talks about Servo at FOSDEM 2026 (videos and slides here):
-
Implementing Streams Spec in Servo – Taym Haddadi (@taym95) described the challenges of implementing the Streams Standard.
-
The Servo project and its impact on the web platform – Manuel Rego (@rego) highlighted the ways that Servo has shaped the web platform and contributed to web standards since it started in 2012.
Mozilla Localization (L10N): Localizer Spotlight: Marcelo
About You
My name is Marcelo Poli. I live in Argentina, and I speak Spanish and English. I started contributing to Mozilla localization with Phoenix 0.3 — 24 years ago.
Mozilla Localization Journey
Q: How did you first get involved in localizing Mozilla products?
A: There was a time when alternative browsers were incompatible with many websites. “Best with IE” appeared everywhere. Then Mozilla was reborn with Phoenix. It was just the browser — unlike Mozilla Suite (the old name for SeaMonkey) — and it was the best option.
At first, it was only available in English, so I searched and found an opportunity to localize my favorite browser. There were already some Spanish localization for the Suite, and that became the base for my work. It took me two releases to complete it, and Phoenix 0.3 shipped with a full language pack — the first Spanish localization in Phoenix history.
The most amazing part was that Mozilla let me do it.
Q: Do you have a favorite product? Do you use the ones you localize regularly?
A: Firefox is always my favorite. Thunderbird comes second — it’s the simplest and most powerful email software. Firefox has been my default browser since the Phoenix era, and since many Mozilla products are connected, working on one often makes you want to contribute to others as well.
Q: What moments stand out from your localization journey?
A: Being part of the Firefox 1.0 release was incredible. The whole world was talking about the new browser, and my localization was part of it.
Another unforgettable moment was seeing my name — along with hundreds of others — on the Mozilla Monument in San Francisco.
Q: Have you shared your work with family and friends?
A: Yes. I usually say, “Try this, it’s better,” and many times they agree. Sometimes I have to explain the concept of free software. When they say, “But I didn’t pay for the other browsers,” I use the classic explanation: “Free as in freedom and free as in free beer.”
I wear Mozilla T-shirts, but I don’t brag about managing the Argentinian localization. Still, some tech-savvy friends have found my name in the credits.
Community & Collaboration
Q: How does the Argentinian localization community work together today?

Marcelo (right) with fellow Argentinian Mozillians
Gabriela and Guillermo
A: In the beginning, the Suite localization, Firefox localization, and the Argentinian community were separate. Mozilla encouraged us to join forces, and I eventually became the l10n manager.The community has grown and shrunk over time. Right now it’s smaller, but localization remains the most active part, keeping products up to date. We stay in touch through an old mailing list, Matrix, and direct messages. I’ve also participated in many community events, although living far from Buenos Aires limits how often I can attend.
Q: How do you coordinate translation, review, and testing?
A: We’re a small group, which actually makes coordination easier. Since we contribute in our free time, even small contributions matter, and three people can approve strings at any time.
We test using Nightly as our main browser. Priorities are set in Pontoon — once the five-star products are complete, we move on to others. Usually, the number of untranslated strings is small, so it’s manageable.
Q: How has your role evolved over time?
A: The old Mozilla folks — the “original cast,” you could say — were essential in the early days. Before collaborative tools existed, I explained DTD and properties file structures to others. Some contributors had strong language skills but less technical background.
Since the Phoenix years, I’ve been responsible for es-AR localization. At first, I worked alone; later others joined. Today, I hold the manager title in Pontoon. As Uncle Ben once said, “With great power comes great responsibility,” so I check Pontoon daily.
Q: What best practices would you share with other localizers?
A: Pontoon is easy to use. The key is respecting terminology and staying consistent across the localization.
If you find a typo or a better phrasing, suggest it directly in Pontoon. You don’t need to contact a manager, and it doesn’t matter how small the change is. Every contribution matters — even if it isn’t approved.
Professional Background & Skills
Q: What is your professional background, and how has it helped your localization work?
A: I studied programming, so I understand software structure and how it works. That helped a lot in the early days when localization required editing files directly — especially dealing with encoding and file structure.
Knowledge of web development also helped with Developer Tools strings, and as a heavy user, I’m familiar with the terminology for almost everything you can do in software.
Q: What have you gained beyond translation?
A: Mozilla allows you to be part of something global — meeting people from different countries and learning how similar or different we are. Through community events and hackathons, I learned how to collaborate internationally. As a side effect, I became more fluent speaking English face to face than I expected.
Q: After so many years, what keeps you motivated?
A: My main motivation is being able to use Mozilla products in my own language. Mozilla is unique in having four Spanish localization. Most projects offer only one for all Spanish-speaking countries — or at best, one for Spain and one for Latin America.
I’m not the most social person in the community, so recruiting isn’t really my role. The best way I motivate others is simply by continuing to work on the projects. Many years ago, I contributed a few strings to Ubuntu localization — maybe they’re still there.
Fun Facts

Marcelo as a DJ
I was a radio DJ for many years — sometimes just playing music, sometimes talking about it.
Paraphrasing Sting, I was born in the ’60s and witnessed the first home computers like Texas Instruments and Commodore. My first personal computer was pre-Windows, with text-based screens, and I used Netscape Navigator on dial-up.
I still prefer a big screen over a cellphone and mechanical keyboards over on-screen ones. These days, I’m learning how to build mobile apps.
Niko Matsakis: How Dada enables internal references
In my previous Dada blog post, I talked about how Dada enables composable sharing. Today I’m going to start diving into Dada’s permission system; permissions are Dada’s equivalent to Rust’s borrow checker.
Goal: richer, place-based permissionsDada aims to exceed Rust’s capabilities by using place-based permissions. Dada lets you write functions and types that capture both a value and things borrowed from that value.
As a fun example, imagine you are writing some Rust code to process a comma-separated list, just looking for entries of length 5 or more:
let list: String = format!("...something big, with commas..."); let items: Vec<&str> = list .split(",") .map(|s| s.trim()) // strip whitespace .filter(|s| s.len() > 5) .collect();One of the cool things about Rust is how this code looks a lot like some high-level language like Python or JavaScript, but in those languages the split call is going to be doing a lot of work, since it will have to allocate tons of small strings, copying out the data. But in Rust the &str values are just pointers into the original string and so split is very cheap. I love this.
On the other hand, suppose you want to package up some of those values, along with the backing string, and send them to another thread to be processed. You might think you can just make a struct like so…
struct Message { list: String, items: Vec<&str>, // ---- // goal is to hold a reference // to strings from list }…and then create the list and items and store them into it:
let list: String = format!("...something big, with commas..."); let items: Vec<&str> = /* as before */; let message = Message { list, items }; // ---- // | // This *moves* `list` into the struct. // That in turn invalidates `items`, which // is borrowed from `list`, so there is no // way to construct `Message`.But as experienced Rustaceans know, this will not work. When you have borrowed data like an &str, that data cannot be moved. If you want to handle a case like this, you need to convert from &str into sending indices, owned strings, or some other solution. Argh!
Dada’s permissions use places, not lifetimesDada does things a bit differently. The first thing is that, when you create a reference, the resulting type names the place that the data was borrowed from, not the lifetime of the reference. So the type annotation for items would say ref[list] String1 (at least, if you wanted to write out the full details rather than leaving it to the type inferencer):
let list: given String = "...something big, with commas..." let items: given Vec[ref[list] String] = list .split(",") .map(_.trim()) // strip whitespace .filter(_.len() > 5) // ------- I *think* this is the syntax I want for closures? // I forget what I had in mind, it's not implemented. .collect()I’ve blogged before about how I would like to redefine lifetimes in Rust to be places as I feel that a type like ref[list] String is much easier to teach and explain: instead of having to explain that a lifetime references some part of the code, or what have you, you can say that “this is a String that references the variable list”.
But what’s also cool is that named places open the door to more flexible borrows. In Dada, if you wanted to package up the list and the items, you could build a Message type like so:
class Message( list: String items: Vec[ref[self.list] String] // --------- // Borrowed from another field! ) // As before: let list: String = "...something big, with commas..." let items: Vec[ref[list] String] = list .split(",") .map(_.strip()) // strip whitespace .filter(_.len() > 5) .collect() // Create the message, this is the fun part! let message = Message(list.give, items.give)Note that last line – Message(list.give, items.give). We can create a new class and move list into it along with items, which borrows from list. Neat, right?
OK, so let’s back up and talk about how this all works.
References in Dada are the defaultLet’s start with syntax. Before we tackle the Message example, I want to go back to the Character example from previous posts, because it’s a bit easier for explanatory purposes. Here is some Rust code that declares a struct Character, creates an owned copy of it, and then gets a few references into it.
struct Character { name: String, class: String, hp: u32, } let ch: Character = Character { name: format!("Ferris"), class: format!("Rustacean"), hp: 22 }; let p: &Character = &ch; let q: &String = &p.name;The Dada equivalent to this code is as follows:
class Character( name: String, klass: String, hp: u32, ) let ch: Character = Character("Tzara", "Dadaist", 22) let p: ref[ch] Character = ch let q: ref[p] String = p.nameThe first thing to note is that, in Dada, the default when you name a variable or a place is to create a reference. So let p = ch doesn’t move ch, as it would in Rust, it creates a reference to the Character stored in ch. You could also explicitly write let p = ch.ref, but that is not preferred. Similarly, let q = p.name creates a reference to the value in the field name. (If you wanted to move the character, you would write let ch2 = ch.give, not let ch2 = ch as in Rust.)
Notice that I said let p = ch “creates a reference to the Character stored in ch”. In particular, I did not say “creates a reference to ch”. That’s a subtle choice of wording, but it has big implications.
References in Dada are not pointersThe reason I wrote that let p = ch “creates a reference to the Character stored in ch” and not “creates a reference to ch” is because, in Dada, references are not pointers. Rather, they are shallow copies of the value, very much like how we saw in the previous post that a shared Character acts like an Arc<Character> but is represented as a shallow copy.
So where in Rust the following code…
let ch = Character { ... }; let p = &ch; let q = &ch.name;…looks like this in memory…
# Rust memory representation Stack Heap ───── ──── ┌───► ch: Character { │ ┌───► name: String { │ │ buffer: ───────────► "Ferris" │ │ length: 6 │ │ capacity: 12 │ │ }, │ │ ... │ │ } │ │ └──── p │ └── qin Dada, code like this
let ch = Character(...) let p = ch let q = ch.namewould look like so
# Dada memory representation Stack Heap ───── ──── ch: Character { name: String { buffer: ───────┬───► "Ferris" length: 6 │ capacity: 12 │ }, │ .. │ } │ │ p: Character { │ name: String { │ buffer: ───────┤ length: 6 │ capacity: 12 │ ... │ } │ } │ │ q: String { │ buffer: ───────────────┘ length: 6 capacity: 12 }Clearly, the Dada representation takes up more memory on the stack. But note that it doesn’t duplicate the memory in the heap, which tends to be where the vast majority of the data is found.
Dada talks about values not referencesThis gets at something important. Rust, like C, makes pointers first-class. So given x: &String, x refers to the pointer and *x refers to its referent, the String.
Dada, like Java, goes another way. x: ref String is a String value – including in memory representation! The difference between a given String, shared String, and ref String is not in their memory layout, all of them are the same, but they differ in whether they own their contents.2
So in Dada, there is no *x operation to go from “pointer” to “referent”. That doesn’t make sense. Your variable always contains a string, but the permissions you have to use that string will change.
In fact, the goal is that people don’t have to learn the memory representation as they learn Dada, you are supposed to be able to think of Dada variables as if they were all objects on the heap, just like in Java or Python, even though in fact they are stored on the stack.3
Rust does not permit moves of borrowed dataIn Rust, you cannot move values while they are borrowed. So if you have code like this that moves ch into ch1…
let ch = Character { ... }; let name = &ch.name; // create reference let ch1 = ch; // moves `ch`…then this code only compiles if name is not used again:
let ch = Character { ... }; let name = &ch.name; // create reference let ch1 = ch; // ERROR: cannot move while borrowed let name1 = name; // use reference again …but Dada canThere are two reasons that Rust forbids moves of borrowed data:
- References are pointers, so those pointers may become invalidated. In the example above, name points to the stack slot for ch, so if ch were to be moved into ch1, that makes the reference invalid.
- The type system would lose track of things. Internally, the Rust borrow checker has a kind of “indirection”. It knows that ch is borrowed for some span of the code (a “lifetime”), and it knows that the lifetime in the type of name is related to that lifetime, but it doesn’t really know that name is borrowed from ch in particular.4
Neither of these apply to Dada:
- Because references are not pointers into the stack, but rather shallow copies, moving the borrowed value doesn’t invalidate their contents. They remain valid.
- Because Dada’s types reference actual variable names, we can modify them to reflect moves.
OK, let’s revisit that Rust example that was giving us an error. When we convert it to Dada, we find that it type checks just fine:
class Character(...) // as before let ch: given Character = Character(...) let name: ref[ch.name] String = ch.name // -- originally it was borrowed from `ch` let ch1 = ch.give // ------- but `ch` was moved to `ch1` let name1: ref[ch1.name] = name // --- now it is borrowed from `ch1`Woah, neat! We can see that when we move from ch into ch1, the compiler updates the types of the variables around it. So actually the type of name changes to ref[ch1.name] String. And then when we move from name to name1, that’s totally valid.
In PL land, updating the type of a variable from one thing to another is called a “strong update”. Obviously things can get a bit complicated when control-flow is involved, e.g., in a situation like this:
let ch = Character(...) let ch1 = Character(...) let name = ch.name if some_condition_is_true() { // On this path, the type of `name` changes // to `ref[ch1.name] String`, and so `ch` // is no longer considered borrowed. ch1 = ch.give ch = Character(...) // not borrowed, we can mutate } else { // On this path, the type of `name` // remains unchanged, and `ch` is borrowed. } // Here, the types are merged, so the // type of `name` is `ref[ch.name, ch1.name] String`. // Therefore, `ch` is considered borrowed here. Renaming lets us call functions with borrowed valuesOK, let’s take the next step. Let’s define a Dada function that takes an owned value and another value borrowed from it, like the name, and then call it:
fn character_and_name( ch1: given Character, name1: ref[ch1] String, ) { // ... does something ... }We could call this function like so, as you might expect:
let ch = Character(...) let name = ch.name character_and_name(ch.give, name)So…how does this work? Internally, the type checker type-checks a function call by creating a simpler snippet of code, essentially, and then type-checking that. It’s like desugaring but only at type-check time. In this simpler snippet, there are a series of let statements to create temporary variables for each argument. These temporaries always have an explicit type taken from the method signature, and they are initialized with the values of each argument:
// type checker "desugars" `character_and_name(ch.give, name)` // into more primitive operations: let tmp1: given Character = ch.give // --------------- ------- // | taken from the call // taken from fn sig let tmp2: ref[tmp1.name] String = name // --------------------- ---- // | taken from the call // taken from fn sig, // but rewritten to use the new // temporariesIf this type checks, then the type checker knows you have supplied values of the required types, and so this is a valid call. Of course there are a few more steps, but that’s the basic idea.
Notice what happens if you supply data borrowed from the wrong place:
let ch = Character(...) let ch1 = Character(...) character_and_name(ch, ch1.name) // --- wrong place!This will fail to type check because you get:
let tmp1: given Character = ch.give let tmp2: ref[tmp1.name] String = ch1.name // -------- // has type `ref[ch1.name] String`, // not `ref[tmp1.name] String` Class constructors are “just” special functionsSo now, if we go all the way back to our original example, we can see how the Message example worked:
class Message( list: String items: Vec[ref[self.list] String] )Basically, when you construct a Message(list, items), that’s “just another function call” from the type system’s perspective, except that self in the signature is handled carefully.
This is modeled, not implementedI should be clear, this system is modeled in the dada-model repository, which implements a kind of “mini Dada” that captures what I believe to be the most interesting bits. I’m working on fleshing out that model a bit more, but it’s got most of what I showed you here.5 For example, here is a test that you get an error when you give a reference to the wrong value.
The “real implementation” is lagging quite a bit, and doesn’t really handle the interesting bits yet. Scaling it up from model to real implementation involves solving type inference and some other thorny challenges, and I haven’t gotten there yet – though I have some pretty interesting experiments going on there too, in terms of the compiler architecture.6
This could apply to RustI believe we could apply most of this system to Rust. Obviously we’d have to rework the borrow checker to be based on places, but that’s the straight-forward part. The harder bit is the fact that &T is a pointer in Rust, and that we cannot readily change. However, for many use cases of self-references, this isn’t as important as it sounds. Often, the data you wish to reference is living in the heap, and so the pointer isn’t actually invalidated when the original value is moved.
Consider our opening example. You might imagine Rust allowing something like this in Rust:
struct Message { list: String, items: Vec<&{self.list} str>, }In this case, the str data is heap-allocated, so moving the string doesn’t actually invalidate the &str value (it would invalidate an &String value, interestingly).
In Rust today, the compiler doesn’t know all the details of what’s going on. String has a Deref impl and so it’s quite opaque whether str is heap-allocated or not. But we are working on various changes to this system in the Beyond the & goal, most notably the Field Projections work. There is likely some opportunity to address this in that context, though to be honest I’m behind in catching up on the details.
-
I’ll note in passing that Dada unifies str and String into one type as well. I’ll talk in detail about how that works in a future blog post. ↩︎
-
This is kind of like C++ references (e.g., String&), which also act “as if” they were a value (i.e., you write s.foo(), not s->foo()), but a C++ reference is truly a pointer, unlike a Dada ref. ↩︎
-
This goal was in part inspired by a conversation I had early on within Amazon, where a (quite experienced) developer told me, “It took me months to understand what variables are in Rust”. ↩︎
-
I explained this some years back in a talk on Polonius at Rust Belt Rust, if you’d like more detail. ↩︎
-
No closures or iterator chains! ↩︎
-
As a teaser, I’m building it in async Rust, where each inference variable is a “future” and use “await” to find out when other parts of the code might have added constraints. ↩︎
Hacks.Mozilla.Org: Why is WebAssembly a second-class language on the web?
This post is an expanded version of a presentation I gave at the 2025 WebAssembly CG meeting in Munich.
WebAssembly has come a long way since its first release in 2017. The first version of WebAssembly was already a great fit for low-level languages like C and C++, and immediately enabled many new kinds of applications to efficiently target the web.
Since then, the WebAssembly CG has dramatically expanded the core capabilities of the language, adding shared memories, SIMD, exception handling, tail calls, 64-bit memories, and GC support, alongside many smaller improvements such as bulk memory instructions, multiple returns, and reference values.
These additions have allowed many more languages to efficiently target WebAssembly. There’s still more important work to do, like stack switching and improved threading, but WebAssembly has narrowed the gap with native in many ways.
Yet, it still feels like something is missing that’s holding WebAssembly back from wider adoption on the Web.
There are multiple reasons for this, but the core issue is that WebAssembly is a second-class language on the web. For all of the new language features, WebAssembly is still not integrated with the web platform as tightly as it should be.
This leads to a poor developer experience, which pushes developers to only use WebAssembly when they absolutely need it. Oftentimes JavaScript is simpler and “good enough”. This means its users tend to be large companies with enough resources to justify the investment, which then limits the benefits of WebAssembly to only a small subset of the larger Web community.
Solving this issue is hard, and the CG has been focused on extending the WebAssembly language. Now that the language has matured significantly, it’s time to take a closer look at this. We’ll go deep into the problem, before talking about how WebAssembly Components could improve things.
What makes WebAssembly second-class?At a very high level, the scripting part of the web platform is layered like this:
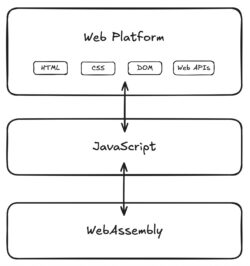
WebAssembly can directly interact with JavaScript, which can directly interact with the web platform. WebAssembly can access the web platform, but only by using the special capabilities of JavaScript. JavaScript is a first-class language on the web, and WebAssembly is not.
This wasn’t an intentional or malicious design decision; JavaScript is the original scripting language of the Web and co-evolved with the platform. Nonetheless, this design significantly impacts users of WebAssembly.
What are these special capabilities of JavaScript? For today’s discussion, there are two major ones:
- Loading of code
- Using Web APIs
WebAssembly code is unnecessarily cumbersome to load. Loading JavaScript code is as simple as just putting it in a script tag:
<script src="script.js"></script>WebAssembly is not supported in script tags today, so developers need to use the WebAssembly JS API to manually load and instantiate code.
let bytecode = fetch(import.meta.resolve('./module.wasm')); let imports = { ... }; let { exports } = await WebAssembly.instantiateStreaming(bytecode, imports);The exact sequence of API calls to use is arcane, and there are multiple ways to perform this process, each of which has different tradeoffs that are not clear to most developers. This process generally just needs to be memorized or generated by a tool for you.
Thankfully, there is the esm-integration proposal, which is already implemented in bundlers today and which we are actively implementing in Firefox. This proposal lets developers import WebAssembly modules from JS code using the familiar JS module system.
import { run } from "/module.wasm"; run();In addition, it allows a WebAssembly module to be loaded directly from a script tag using type=”module”:
<script type="module" src="/module.wasm"></script>This streamlines the most common patterns for loading and instantiating WebAssembly modules. However, while this mitigates the initial difficulty, we quickly run into the real problem.
Using Web APIsUsing a Web API from JavaScript is as simple as this:
console.log("hello, world");For WebAssembly, the situation is much more complicated. WebAssembly has no direct access to Web APIs and must use JavaScript to access them.
The same single-line console.log program requires the following JavaScript file:
// We need access to the raw memory of the Wasm code, so // create it here and provide it as an import. let memory = new WebAssembly.Memory(...); function consoleLog(messageStartIndex, messageLength) { // The string is stored in Wasm memory, but we need to // decode it into a JS string, which is what DOM APIs // require. let messageMemoryView = new UInt8Array( memory.buffer, messageStartIndex, messageLength); let messageString = new TextDecoder().decode(messageMemoryView); // Wasm can't get the `console` global, or do // property lookup, so we do that here. return console.log(messageString); } // Pass the wrapped Web API to the Wasm code through an // import. let imports = { "env": { "memory": memory, "consoleLog": consoleLog, }, }; let { instance } = await WebAssembly.instantiateStreaming(bytecode, imports); instance.exports.run();And the following WebAssembly file:
(module ;; import the memory from JS code (import "env" "memory" (memory 0)) ;; import the JS consoleLog wrapper function (import "env" "consoleLog" (func $consoleLog (param i32 i32)) ) ;; export a run function (func (export "run") (local i32 $messageStartIndex) (local i32 $messageLength) ;; create a string in Wasm memory, store in locals ... ;; call the consoleLog method local.get $messageStartIndex local.get $messageLength call $consoleLog ) )Code like this is called “bindings” or “glue code” and acts as the bridge between your source language (C++, Rust, etc.) and Web APIs.
This glue code is responsible for re-encoding WebAssembly data into JavaScript data and vice versa. For example, when returning a string from JavaScript to WebAssembly, the glue code may need to call a malloc function in the WebAssembly module and re-encode the string at the resulting address, after which the module is responsible for eventually calling free.
This is all very tedious, formulaic, and difficult to write, so it is typical to generate this glue automatically using tools like embind or wasm-bindgen. This streamlines the authoring process, but adds complexity to the build process that native platforms typically do not require. Furthermore, this build complexity is language-specific; Rust code will require different bindings from C++ code, and so on.
Of course, the glue code also has runtime costs. JavaScript objects must be allocated and garbage collected, strings must be re-encoded, structs must be deserialized. Some of this cost is inherent to any bindings system, but much of it is not. This is a pervasive cost that you pay at the boundary between JavaScript and WebAssembly, even when the calls themselves are fast.
This is what most people mean when they ask “When is Wasm going to get DOM support?” It’s already possible to access any Web API with WebAssembly, but it requires JavaScript glue code.
Why does this matter?From a technical perspective, the status quo works. WebAssembly runs on the web and many people have successfully shipped software with it.
From the average web developer’s perspective, though, the status quo is subpar. WebAssembly is too complicated to use on the web, and you can never escape the feeling that you’re getting a second class experience. In our experience, WebAssembly is a power user feature that average developers don’t use, even if it would be a better technical choice for their project.
The average developer experience for someone getting started with JavaScript is something like this:
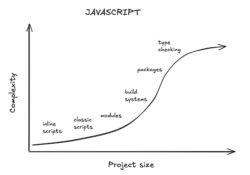
There’s a nice gradual curve where you use progressively more complicated features as the scope of your project increases.
By comparison, the average developer experience for someone getting started with WebAssembly is something like this:
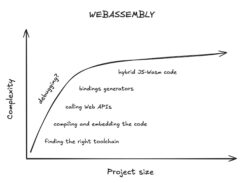
You immediately must scale “the wall” of wrangling the many different pieces to work together. The end result is often only worth it for large projects.
Why is this the case? There are several reasons, and they all directly stem from WebAssembly being a second class language on the web.
1. It’s difficult for compilers to provide first-class support for the webAny language targeting the web can’t just generate a Wasm file, but also must generate a companion JS file to load the Wasm code, implement Web API access, and handle a long tail of other issues. This work must be redone for every language that wants to support the web, and it can’t be reused for non-web platforms.
Upstream compilers like Clang/LLVM don’t want to know anything about JS or the web platform, and not just for lack of effort. Generating and maintaining JS and web glue code is a specialty skill that is difficult for already stretched-thin maintainers to justify. They just want to generate a single binary, ideally in a standardized format that can also be used on platforms besides the web.
2. Standard compilers don’t produce WebAssembly that works on the webThe result is that support for WebAssembly on the web is often handled by third-party unofficial toolchain distributions that users need to find and learn. A true first-class experience would start with the tool that users already know and have installed.
This is, unfortunately, many developers’ first roadblock when getting started with WebAssembly. They assume that if they just have rustc installed and pass a –target=wasm flag that they’ll get something they could load in a browser. You may be able to get a WebAssembly file doing that, but it will not have any of the required platform integration. If you figure out how to load the file using the JS API, it will fail for mysterious and hard-to-debug reasons. What you really need is the unofficial toolchain distribution which implements the platform integration for you.
3. Web documentation is written for JavaScript developersThe web platform has incredible documentation compared to most tech platforms. However, most of it is written for JavaScript. If you don’t know JavaScript, you’ll have a much harder time understanding how to use most Web APIs.
A developer wanting to use a new Web API must first understand it from a JavaScript perspective, then translate it into the types and APIs that are available in their source language. Toolchain developers can try to manually translate the existing web documentation for their language, but that is a tedious and error prone process that doesn’t scale.
4. Calling Web APIs can still be slowIf you look at all of the JS glue code for the single call to console.log above, you’ll see that there is a lot of overhead. Engines have spent a lot of time optimizing this, and more work is underway. Yet this problem still exists. It doesn’t affect every workload, but it’s something every WebAssembly user needs to be careful about.
Benchmarking this is tricky, but we ran an experiment in 2020 to precisely measure the overhead that JS glue code has in a real world DOM application. We built the classic TodoMVC benchmark in the experimental Dodrio Rust framework and measured different ways of calling DOM APIs.
Dodrio was perfect for this because it computed all the required DOM modifications separately from actually applying them. This allowed us to precisely measure the impact of JS glue code by swapping out the “apply DOM change list” function while keeping the rest of the benchmark exactly the same.
We tested two different implementations:
- “Wasm + JS glue”: A WebAssembly function which reads the change list in a loop, and then asks JS glue code to apply each change individually. This is the performance of WebAssembly today.
- “Wasm only”: A WebAssembly function which reads the change list in a loop, and then uses an experimental direct binding to the DOM which skips JS glue code. This is the performance of WebAssembly if we could skip JS glue code.
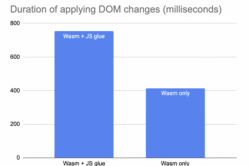
The duration to apply the DOM changes dropped by 45% when we were able to remove JS glue code. DOM operations can already be expensive; WebAssembly users can’t afford to pay a 2x performance tax on top of that. And as this experiment shows, it is possible to remove the overhead.
5. You always need to understand the JavaScript layerThere’s a saying that “abstractions are always leaky”.
The state of the art for WebAssembly on the web is that every language builds their own abstraction of the web platform using JavaScript. But these abstractions are leaky. If you use WebAssembly on the web in any serious capacity, you’ll eventually hit a point where you need to read or write your own JavaScript to make something work.
This adds a conceptual layer which is a burden for developers. It feels like it should just be enough to know your source language, and the web platform. Yet for WebAssembly, we require users to also know JavaScript in order to be a proficient developer.
How can we fix this?This is a complicated technical and social problem, with no single solution. We also have competing priorities for what is the most important problem with WebAssembly to fix first.
Let’s ask ourselves: In an ideal world, what could help us here?
What if we had something that was:
- A standardized self-contained executable artifact
- Supported by multiple languages and toolchains
- Which handles loading and linking of WebAssembly code
- Which supports Web API usage
If such a thing existed, languages could generate these artifacts and browsers could run them, without any JavaScript involved. This format would be easier for languages to support and could potentially exist in standard upstream compilers, runtimes, toolchains, and popular packages without the need for third-party distributions. In effect, we could go from a world where every language re-implements the web platform integration using JavaScript, to sharing a common one that is built directly into the browser.
It would obviously be a lot of work to design and validate a solution! Thankfully, we already have a proposal with these goals that has been in development for years: the WebAssembly Component Model.
What is a WebAssembly Component?For our purposes, a WebAssembly Component defines a high-level API that is implemented with a bundle of low-level WebAssembly code. It’s a standards-track proposal in the WebAssembly CG that’s been in development since 2021.
Already today, WebAssembly Components…
- Can be created from many different programming languages.
- Can be executed in many different runtimes (including in browsers today, with a polyfill).
- Can be linked together to allow code re-use between different languages.
- Allow WebAssembly code to directly call Web APIs.
If you’re interested in more details, check out the Component Book or watch “What is a Component?”.
We feel that WebAssembly Components have the potential to give WebAssembly a first-class experience on the web platform, and to be the missing link described above.
How could they work?Let’s try to re-create the earlier console.log example using only WebAssembly Components and no JavaScript.
NOTE: The interactions between WebAssembly Components and the web platform have not been fully designed, and the tooling is under active development.
Take this as an aspiration for how things could be, not a tutorial or promise.
The first step is to specify which APIs our application needs. This is done using an IDL called WIT. For our example, we need the Console API. We can import it by specifying the name of the interface.
component { import std:web/console; }The std:web/console interface does not exist today, but would hypothetically come from the official WebIDL that browsers use for describing Web APIs. This particular interface might look like this:
package std:web; interface console { log: func(msg: string); ... }Now that we have the above interfaces, we can use them when writing a Rust program that compiles to a WebAssembly Component:
use std::web::console; fn main() { console::log(“hello, world”); }Once we have a component, we can load it into the browser using a script tag.
<script type="module" src="component.wasm"></script>And that’s it! The browser would automatically load the component, bind the native web APIs directly (without any JS glue code), and run the component.
This is great if your whole application is written in WebAssembly. However, most WebAssembly usage is part of a “hybrid application” which also contains JavaScript. We also want to simplify this use case. The web platform shouldn’t be split into “silos” that can’t interact with each other. Thankfully, WebAssembly Components also address this by supporting cross-language interoperability.
Let’s create a component that exports an image decoder for use from JavaScript code. First we need to write the interface that describes the image decoder:
interface image-lib { record pixel { r: u8; g: u8; b: u8; a: u8; } resource image { from-stream: static async func(bytes: stream<u8>) -> result<image>; get: func(x: u32, y: u32) -> pixel; } } component { export image-lib; }Once we have that, we can write the component in any language that supports components. The right language will depend on what you’re building or what libraries you need to use. For this example, I’ll leave the implementation of the image decoder as an exercise for the reader.
The component can then be loaded in JavaScript as a module. The image decoder interface we defined is accessible to JavaScript, and can be used as if you were importing a JavaScript library to do the task.
import { Image } from "image-lib.wasm"; let byteStream = (await fetch("/image.file")).body; let image = await Image.fromStream(byteStream); let pixel = image.get(0, 0); console.log(pixel); // { r: 255, g: 255, b: 0, a: 255 } Next StepsAs it stands today, we think that WebAssembly Components would be a step in the right direction for the web. Mozilla is working with the WebAssembly CG to design the WebAssembly Component Model. Google is also evaluating it at this time.
If you’re interested to try this out, learn to build your first component and try it out in the browser using Jco or from the command-line using Wasmtime. The tooling is under heavy development, and contributions and feedback are welcome. If you’re interested in the in-development specification itself, check out the component-model proposal repository.
WebAssembly has come very far from when it was first released in 2017. I think the best is still yet to come if we’re able to turn it from being a “power user” feature, to something that average developers can benefit from.
The post Why is WebAssembly a second-class language on the web? appeared first on Mozilla Hacks - the Web developer blog.
The Mozilla Blog: How to turn off AI features in Firefox, or choose the ones you want
Other browsers force AI features on users. Firefox gives you a choice.
In the latest desktop version of Firefox, you’ll find an AI controls section where you can turn off AI features entirely — or decide which ones stay on. Here’s how to set things up the way you want.
But first, what AI features can you manage in Firefox?AI is a broad term. Traditional machine learning — like systems that classify, rank or personalize an experience — have been part of browsers for a while.
AI controls focus on newer AI-enhanced features on Firefox, including website translations, image alt text in PDFs, AI-enhanced tab groups, link previews and an AI chatbot in the sidebar.
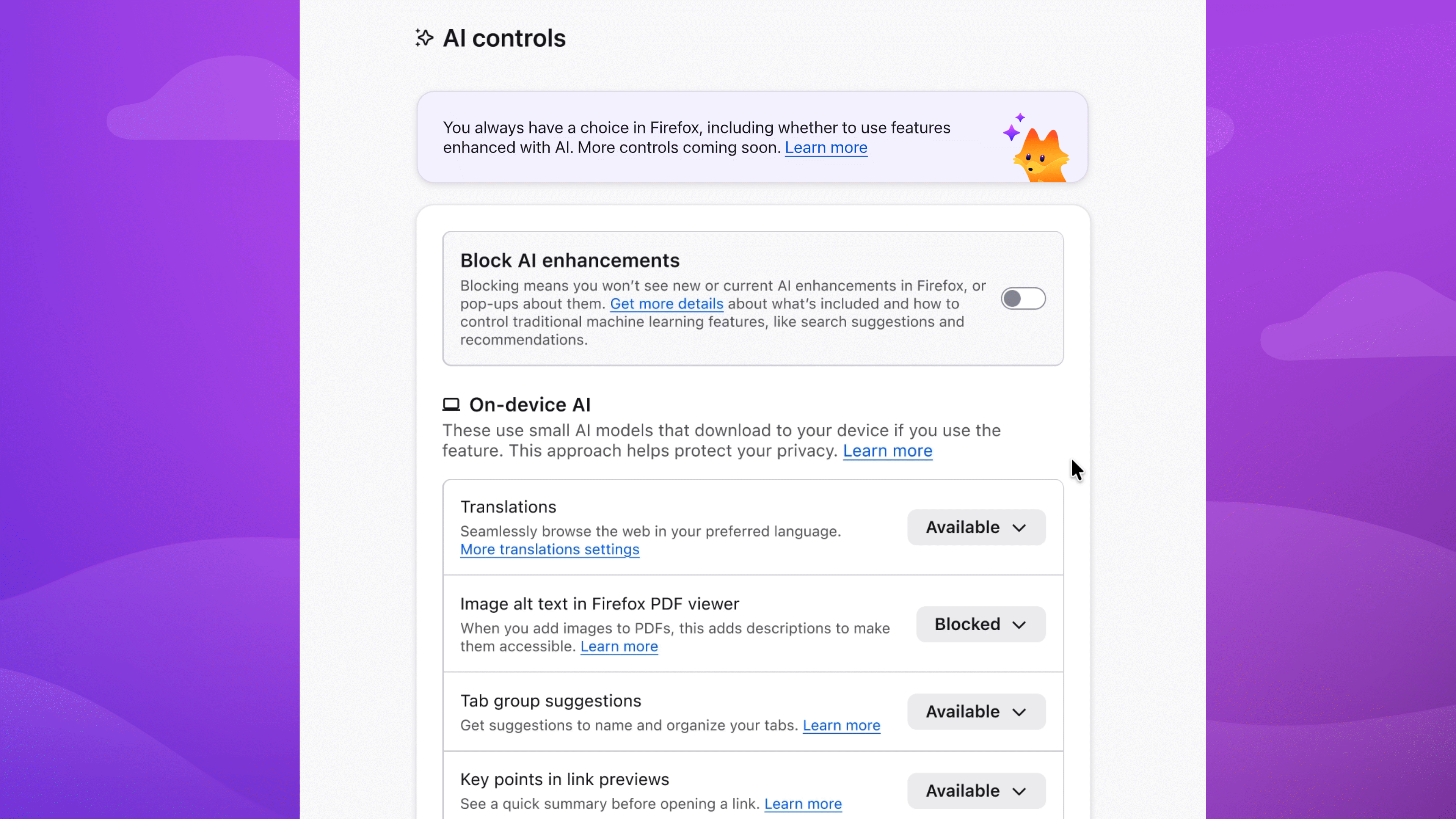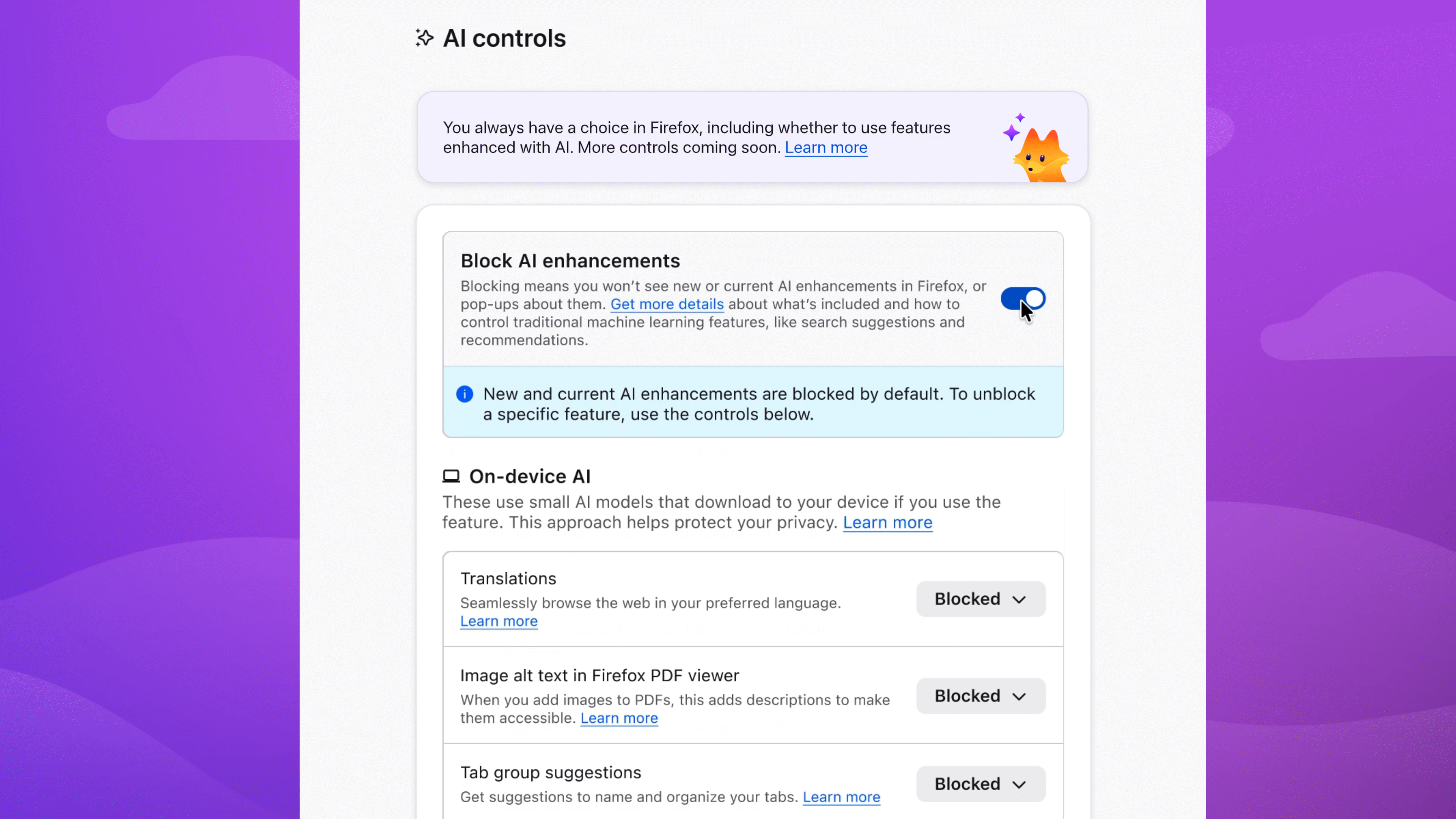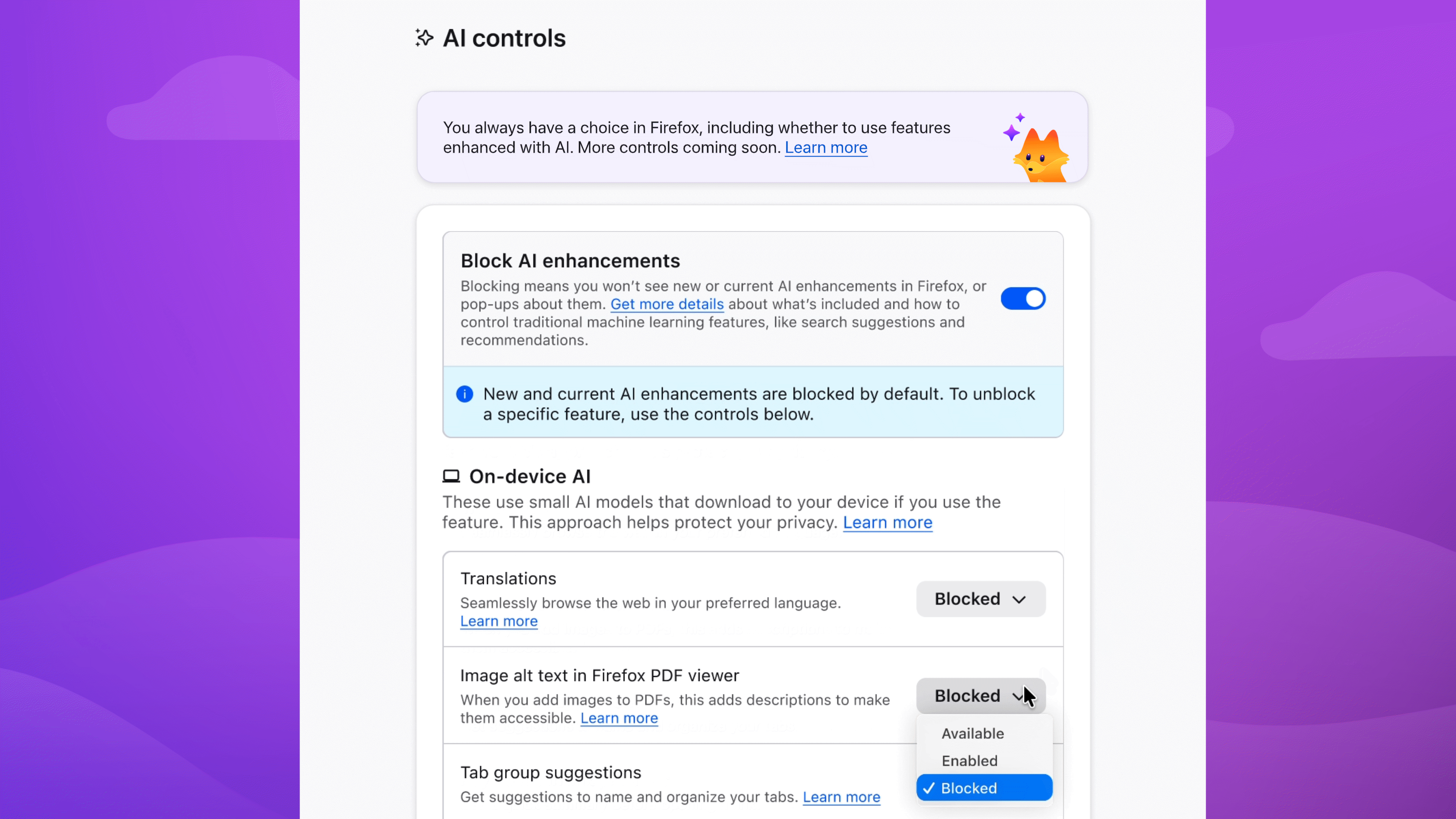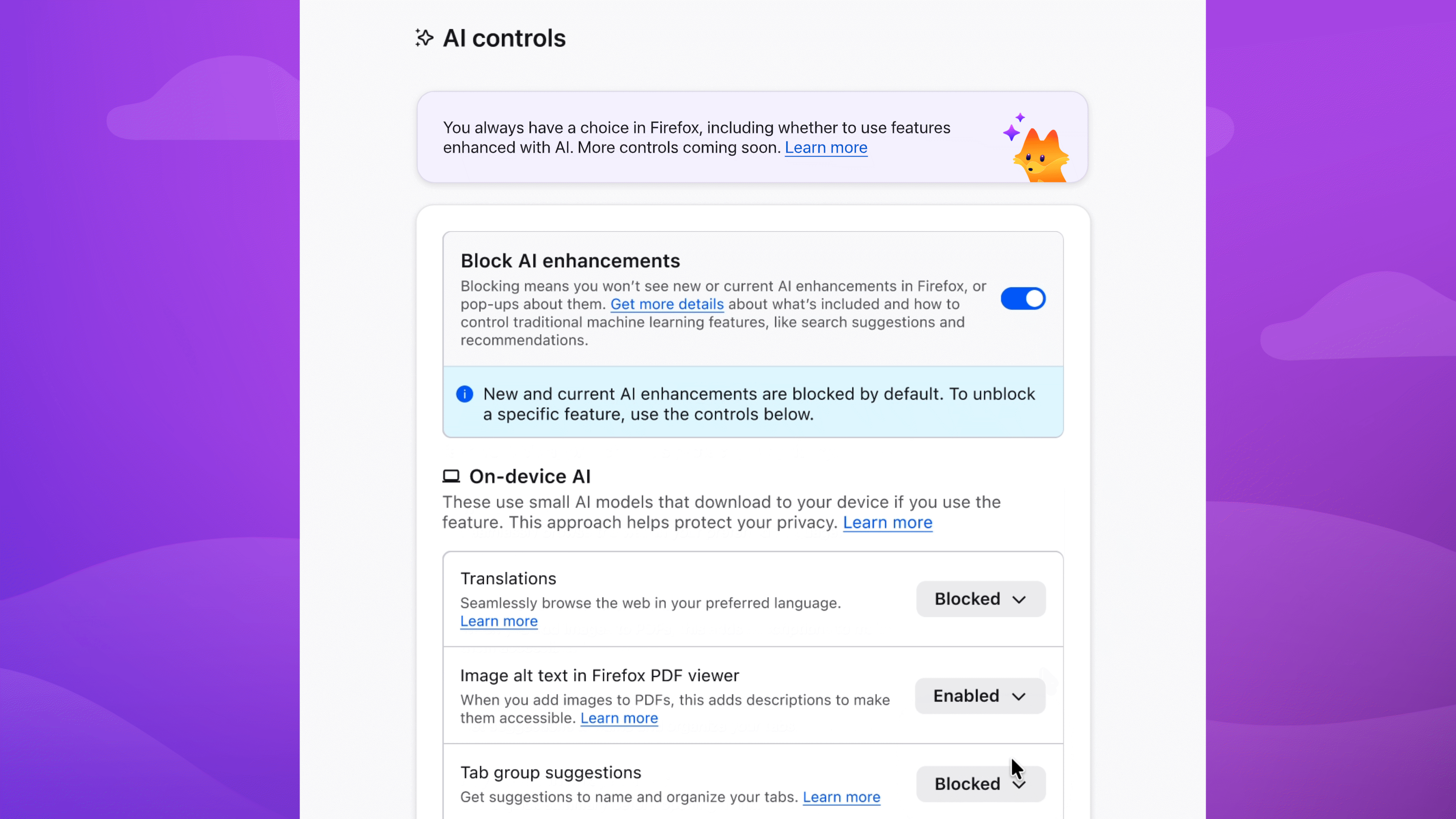
To block current and future AI-enhanced features:
- Menu bar > Firefox > Settings (or Preferences) > AI Controls
- Turn on Block AI enhancements
You can also manage AI features individually. Block link previews? Up to you. Change your mind on translations? You can turn them on any time, while keeping all other AI features blocked.
To block specific features:
- Menu bar > Firefox > Settings (or Preferences) > AI Controls
- Find the AI feature > dropdown menu > Blocked
In the dropdown menu, Available means you can see and use the feature; Enabled means you’ve opted in to use it; and Blocked means it’s hidden and can’t be used.
Choose the AI features you want to use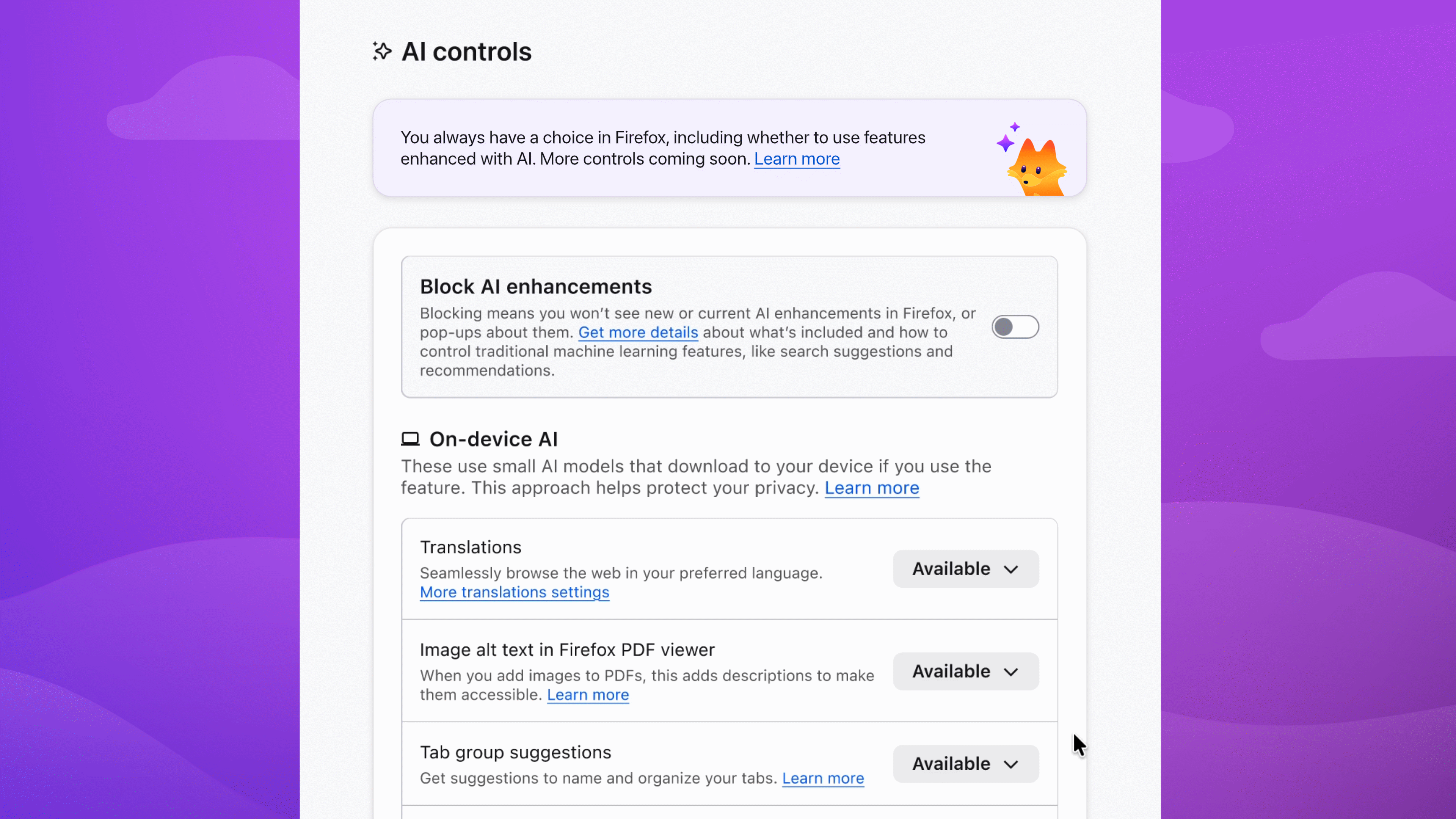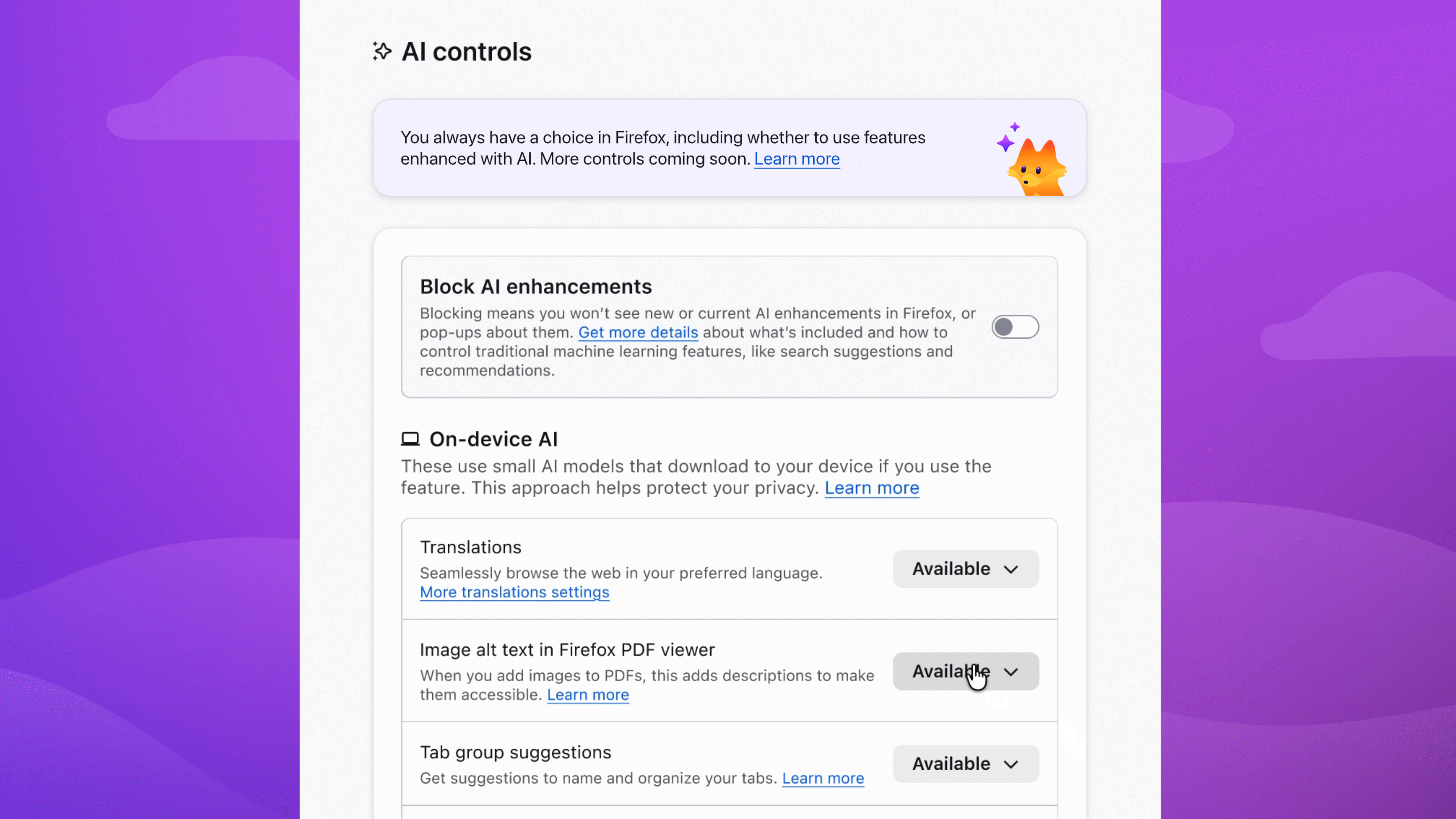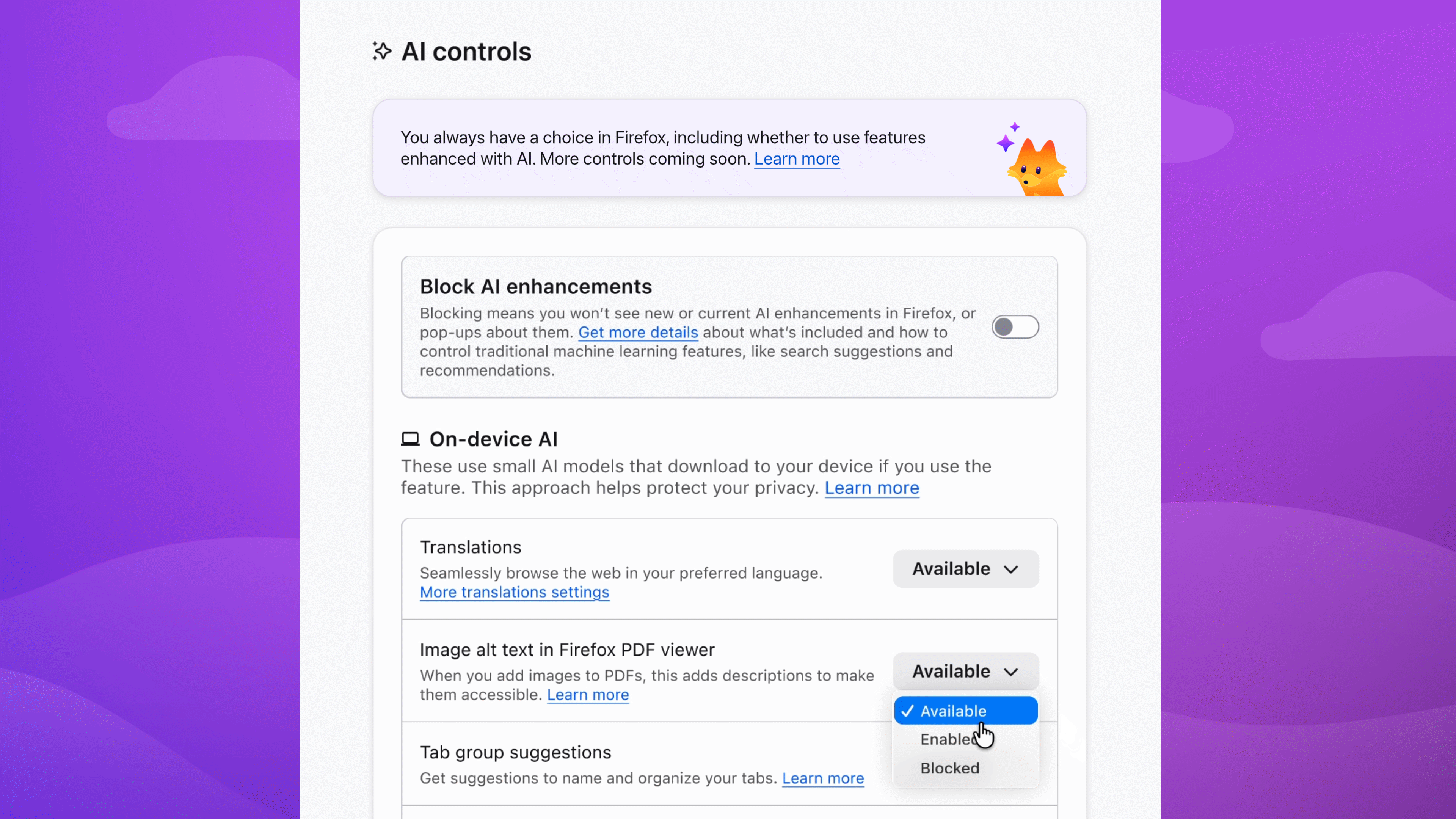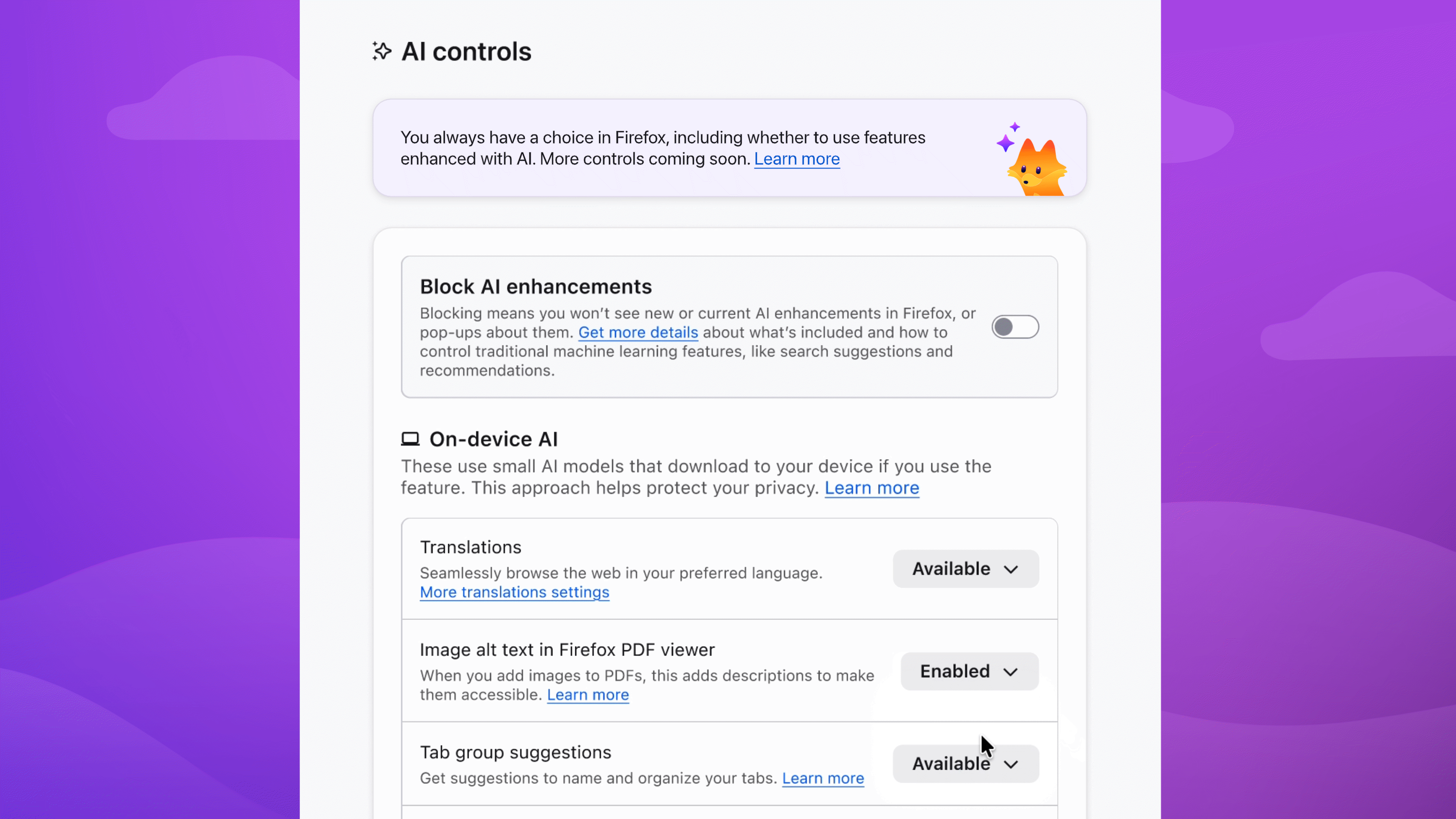
Enable image alt text in PDFs to improve accessibility. Keep AI-enhanced tab group suggestions if they’re useful. Block anything that isn’t — the decision is yours.
You can update your choices in Setting anytime.
For more details on AI controls, head to our Mozilla Support page. Have feedback? We’d love to hear it on Mozilla Connect – or come chat with us during our Reddit AMA on Feb. 26.
The post How to turn off AI features in Firefox, or choose the ones you want appeared first on The Mozilla Blog.
Firefox Developer Experience: Firefox WebDriver Newsletter 148
WebDriver is a remote control interface that enables introspection and control of user agents. As such it can help developers to verify that their websites are working and performing well with all major browsers. The protocol is standardized by the W3C and consists of two separate specifications: WebDriver classic (HTTP) and the new WebDriver BiDi (Bi-Directional).
This newsletter gives an overview of the work we’ve done as part of the Firefox 148 release cycle.
ContributionsFirefox is an open source project, and we are always happy to receive external code contributions to our WebDriver implementation. We want to give special thanks to everyone who filed issues, bugs and submitted patches.
In Firefox 148, a WebDriver bug was fixed by a contributor:
WebDriver code is written in JavaScript, Python, and Rust so any web developer can contribute! Read how to setup the work environment and check the list of mentored issues for Marionette, or the list of mentored JavaScript bugs for WebDriver BiDi. Join our chatroom if you need any help to get started!
General- Fixed a race condition during initialization of required browser features when opening a new window, preventing issues when navigating immediately to another URL.
- Fixed an interoperability issue between Marionette and WebDriver BiDi where the BiDi clientWindow ID was incorrectly used as a window handle in Marionette.
- Added initial support for interacting with the browser’s chrome scope (the Firefox window itself). The browsingContext.getTree command now accepts the vendor specific moz:scope parameter and returns chrome contexts when set to chrome and Firefox was started with the --remote-allow-system-access argument. These contexts can be used with script.evaluate and script.callFunction to execute privileged JavaScript with access to Gecko APIs. Other commands do not yet support chrome contexts, but support will be added incrementally as needed.
- Updated the emulation.setGeolocationOverride and emulation.setScreenOrientationOverride commands to implement the new reset behavior: contexts are reset only when the contexts parameter is provided, and user contexts only when the userContexts parameter is specified.
- Fixed a race condition in browsingContext.create where opening a new tab in the foreground could return before the document became visible.
- Fixed an issue that occurred when a navigation redirected to an error page.
- Fixed an issue in network.getData that caused a RangeError when decoding chunked response bodies due to a size mismatch.
- Fixed an issue where the browsingContext.userPromptOpened and browsingContext.userPromptClosed events incorrectly reported the top-level context ID instead of the iframe’s context ID.
- Improved the performance of WebDriver BiDi commands by approximately 100 ms when the selected context is no longer available during the command execution.
Hacks.Mozilla.Org: Goodbye innerHTML, Hello setHTML: Stronger XSS Protection in Firefox 148
Cross-site scripting (XSS) remains one of the most prevalent vulnerabilities on the web. The new standardized Sanitizer API provides a straightforward way for web developers to sanitize untrusted HTML before inserting it into the DOM. Firefox 148 is the first browser to ship this standardized security enhancing API, advancing a safer web for everyone. We expect other browsers to follow soon.
An XSS vulnerability arises when a website inadvertently lets attackers inject arbitrary HTML or JavaScript through user-generated content. With this attack, an attacker could monitor and manipulate user interactions and continually steal user data for as long as the vulnerability remains exploitable. XSS has a long history of being notoriously difficult to prevent and has ranked among the top three web vulnerabilities (CWE-79) for nearly a decade.
 Firefox has been deeply involved in solutions for XSS from the beginning, starting with spearheading the Content-Security-Policy (CSP) standard in 2009. CSP allows websites to restrict which resources (scripts, styles, images, etc.) the browser can load and execute, providing a strong line of defense against XSS. Despite a steady stream of improvements and ongoing maintenance, CSP did not gain sufficient adoption to protect the long tail of the web as it requires significant architectural changes for existing web sites and continuous review by security experts.
Firefox has been deeply involved in solutions for XSS from the beginning, starting with spearheading the Content-Security-Policy (CSP) standard in 2009. CSP allows websites to restrict which resources (scripts, styles, images, etc.) the browser can load and execute, providing a strong line of defense against XSS. Despite a steady stream of improvements and ongoing maintenance, CSP did not gain sufficient adoption to protect the long tail of the web as it requires significant architectural changes for existing web sites and continuous review by security experts.
The Sanitizer API is designed to help fill that gap by providing a standardized way to turn malicious HTML into harmless HTML — in other words, to sanitize it. The setHTML( ) method integrates sanitization directly into HTML insertion, providing safety by default. Here is an example of sanitizing a simple unsafe HTML:
document.body.setHTML(`<h1>Hello my name is <img src="x" onclick="alert('XSS')">`);This sanitization will allow the HTML <h1> element while removing the embedded <img> element and its onclick attribute, thereby eliminating the XSS attack resulting in the following safe HTML:
<h1>Hello my name is</h1>Developers can opt into stronger XSS protections with minimal code changes by replacing error-prone innerHTML assignments with setHTML(). If the default configuration of setHTML( ) is too strict (or not strict enough) for a given use case, developers can provide a custom configuration that defines which HTML elements and attributes should be kept or removed. To experiment with the Sanitizer API before introducing it on a web page, we recommend exploring the Sanitizer API playground.
For even stronger protections, the Sanitizer API can be combined with Trusted Types, which centralize control over HTML parsing and injection. Once setHTML( ) is adopted, sites can enable Trusted Types enforcement more easily, often without requiring complex custom policies. A strict policy can allow setHTML( ) while blocking other unsafe HTML insertion methods, helping prevent future XSS regressions.
The Sanitizer API enables an easy replacement of innerHTML assignments with setHTML( ) in existing code, introducing a new safer default to protect users from XSS attacks on the web. Firefox 148 supports the Sanitizer API as well as Trusted Types, which creates a safer web experience. Adopting these standards will allow all developers to prevent XSS without the need for a dedicated security team or significant implementation changes.
Image credits for the illustration above: Website, by Desi Ratna; Person, by Made by Made; Hacker by Andy Horvath.
The post Goodbye innerHTML, Hello setHTML: Stronger XSS Protection in Firefox 148 appeared first on Mozilla Hacks - the Web developer blog.
Firefox Tooling Announcements: Firefox Profiler Deployment (February 24, 2026)
The latest version of the Firefox Profiler is now live! Check out the full changelog below to see what’s changed.
Highlights:
- [fatadel] Provide correct instructions on the home page for Firefox for Android (Fenix) (#5816)
- [Markus Stange] Migrate to esbuild (#5589)
- [Nazım Can Altınova] Make the source table non-optional in the gecko profile format (#5842)
Other Changes:
- [Markus Stange] Move transparent fill check to a less expensive place. (#5826)
- [fatadel] Refine docs for ctrl key (#5831)
- [Nazım Can Altınova] Update the team members inside CONTRIBUTING.md (#5829)
- [Markus Stange] Make markers darker (#5839)
- [Markus Stange] Directly use photon-colors (#5821)
- [Markus Stange] Use data URLs for SVG files. (#5845)
- [Markus Stange] Tweak dark mode colors some more. (#5846)
- [fatadel] fix foreground color of the button on error page (#5849)
- [Nazım Can Altınova]
 Sync: l10n → main (February 24, 2026) (#5855)
Sync: l10n → main (February 24, 2026) (#5855)
Big thanks to our amazing localizers for making this release possible:
- de: Michael Köhler
- el: Jim Spentzos
- en-GB: Ian Neal
- es-CL: ravmn
- fr: Théo Chevalier
- fy-NL: Fjoerfoks
- a: Melo46
- it: Francesco Lodolo [:flod]
- nl: Mark Heijl
- ru: Valery Ledovskoy
- sv-SE: Andreas Pettersson
- zh-TW: Pin-guang Chen
Find out more about the Firefox Profiler on profiler.firefox.com! If you have any questions, join the discussion on our Matrix channel!
1 post - 1 participant
Niko Matsakis: What it means that Ubuntu is using Rust
Righty-ho, I’m back from Rust Nation, and busily horrifying my teenage daughter with my (admittedly atrocious) attempts at doing an English accent1. It was a great trip with a lot of good conversations and some interesting observations. I am going to try to blog about some of them, starting with some thoughts spurred by Jon Seager’s closing keynote, “Rust Adoption At Scale with Ubuntu”.
There are many chasms out thereFor some time now I’ve been debating with myself, has Rust “crossed the chasm”? If you’re not familiar with that term, it comes from a book that gives a kind of “pop-sci” introduction to the Technology Adoption Life Cycle.
The answer, of course, is it depends on who you ask. Within Amazon, where I have the closest view, the answer is that we are “most of the way across”: Rust is squarely established as the right way to build at-scale data planes or resource-aware agents and it is increasingly seen as the right choice for low-level code in devices and robotics as well – but there remains a lingering perception that Rust is useful for “those fancy pants developers at S3” (or wherever) but a bit overkill for more average development3.
On the other hand, within the realm of Safety Critical Software, as Pete LeVasseur wrote in a recent rust-lang blog post, Rust is still scrabbling for a foothold. There are a number of successful products but most of the industry is in a “wait and see” mode, letting the early adopters pave the path.
“Crossing the chasm” means finding “reference customers”The big idea that I at least took away from reading Crossing the Chasm and other references on the technology adoption life cycle is the need for “reference customers”. When you first start out with something new, you are looking for pioneers and early adopters that are drawn to new things:
What an early adopter is buying [..] is some kind of change agent. By being the first to implement this change in the industry, the early adopters expect to get a jump on the competition. – from Crossing the Chasm
But as your technology matures, you have to convince people with a lower and lower tolerance for risk:
The early majority want to buy a productivity improvement for existing operations. They are looking to minimize discontinuity with the old ways. They want evolution, not revolution. – from Crossing the Chasm
So what is most convincing to people to try something new? The answer is seeing that others like them have succeeded.
You can see this at play in both the Amazon example and the Safety Critical Software example. Clearly seeing Rust used for network services doesn’t mean it’s ready to be used in your car’s steering column4. And even within network services, seeing a group like S3 succeed with Rust may convince other groups building at-scale services to try Rust, but doesn’t necessarily persuade a team to use Rust for their next CRUD service. And frankly, it shouldn’t! They are likely to hit obstacles.
Ubuntu is helping Rust “cross the (user-land linux) chasm”All of this was on my mind as I watched the keynote by Jon Seager, the VP of Engineering at Canonical, which is the company behind Ubuntu. Similar to Lars Bergstrom’s epic keynote from year’s past on Rust adoption within Google, Jon laid out a pitch for why Canonical is adopting Rust that was at once visionary and yet deeply practical.
“Visionary and yet deeply practical” is pretty much the textbook description of what we need to cross from early adopters to early majority. We need folks who care first and foremost about delivering the right results, but are open to new ideas that might help them do that better; folks who can stand on both sides of the chasm at once.
Jon described how Canonical focuses their own development on a small set of languages: Python, C/C++, and Go, and how they had recently brought in Rust and were using it as the language of choice for new foundational efforts, replacing C, C++, and (some uses of) Python.
Ubuntu is building the bridge across the chasmJon talked about how he sees it as part of Ubuntu’s job to “pay it forward” by supporting the construction of memory-safe foundational utilities. Jon meant support both in terms of finances – Canonical is sponsoring the Trifecta Tech Foundation’s to develop sudo-rs and ntpd-rs and sponsoring the uutils org’s work on coreutils – and in terms of reputation. Ubuntu can take on the risk of doing something new, prove that it works, and then let others benefit.
Remember how the Crossing the Chasm book described early majority people? They are “looking to minimize discontinuity with the old ways”. And what better way to do that than to have drop-in utilities that fit within their existing workflows.
The challenge for Rust: listening to these new adoptersWith new adoption comes new perspectives. On Thursday night I was at dinner5 organized by Ernest Kissiedu6. Jon Seager was there along with some other Rust adopters from various industries, as were a few others from the Rust Foundation and the open-source project.
Ernest asked them to give us their unvarnished takes on Rust. Jon made the provocative comment that we needed to revisit our policy around having a small standard library. He’s not the first to say something like that, it’s something we’ve been hearing for years and years – and I think he’s right! Though I don’t think the answer is just to ship a big standard library. In fact, it’s kind of a perfect lead-in to (what I hope will be) my next blog post, which is about a project I call “battery packs”7.
To grow, you have to changeThe broader point though is that shifting from targeting “pioneers” and “early adopters” to targeting “early majority” sometimes involves some uncomfortable changes:
Transition between any two adoption segments is normally excruciatingly awkward because you must adopt new strategies just at the time you have become most comfortable with the old ones. [..] The situation can be further complicated if the high-tech company, fresh from its marketing success with visionaries, neglects to change its sales pitch. [..] The company may be saying “state-of-the-art” when the pragmatist wants to hear “industry standard”. – Crossing the Chasm (emphasis mine)
Not everybody will remember it, but in 2016 there was a proposal called the Rust Platform. The idea was to bring in some crates and bless them as a kind of “extended standard library”. People hated it. After all, they said, why not just add dependencies to your Cargo.toml? It’s easy enough. And to be honest, they were right – at least at the time.
I think the Rust Platform is a good example of something that was a poor fit for early adopters, who want the newest thing and don’t mind finding the best crates, but which could be a great fit for the Early Majority.8
Anyway, I’m not here to argue for one thing or another in this post, but more for the concept that we have to be open to adapting our learned wisdom to new circumstances. In the past, we were trying to bootstrap Rust into the industry’s consciousness – and we have succeeded.
The task before us now is different: we need to make Rust the best option not just in terms of “what it could be” but in terms of “what it actually is” – and sometimes those are in tension.
Another challenge for Rust: turning adoption into investmentLater in the dinner, the talk turned, as it often does, to money. Growing Rust adoption also comes with growing needs placed on the Rust project and its ecosystem. How can we connect the dots? This has been a big item on my mind, and I realize in writing this paragraph how many blog posts I have yet to write on the topic, but let me lay out a few interesting points that came up over this dinner and at other recent points.
Investment can mean contribution, particularly for open-source orgsFirst, there are more ways to offer support than $$. For Canonical specifically, as they are an open-source organization through-and-through, what I would most want is to build stronger relationships between our organizations. With the Rust for Linux developers, early on Rust maintainers were prioritizing and fixing bugs on behalf of RfL devs, but more and more, RfL devs are fixing things themselves, with Rust maintainers serving as mentors. This is awesome!
Money often comes before a company has adopted Rust, not afterSecond, there’s an interesting trend about $$ that I’ve seen crop up in a few places. We often think of companies investing in the open-source dependencies that they rely upon. But there’s an entirely different source of funding, and one that might be even easier to tap, which is to look at companies that are considering Rust but haven’t adopted it yet.
For those “would be” adopters, there are often individuals in the org who are trying to make the case for Rust adoption – these individuals are early adopters, people with a vision for how things could be, but they are trying to sell to their early majority company. And to do that, they often have a list of “table stakes” features that need to be supported; what’s more, they often have access to some budget to make these things happen.
This came up when I was talking to Alexandru Radovici, the Foundation’s Silver Member Directory, who said that many safety critical companies have money they’d like to spend to close various gaps in Rust, but they don’t know how to spend it. Jon’s investments in Trifecta Tech and the uutils org have the same character: he is looking to close the gaps that block Ubuntu from using Rust more.
Conclusions…?Well, first of all, you should watch Jon’s talk. “Brilliant”, as the Brits have it.
But my other big thought is that this is a crucial time for Rust. We are clearly transitioning in a number of areas from visionaries and early adopters towards that pragmatic majority, and we need to be mindful that doing so may require us to change some of the way that we’ve always done things. I liked this paragraph from Crossing the Chasm:
To market successfully to pragmatists, one does not have to be one – just understand their values and work to serve them. To look more closely into these values, if the goal of visionaries is to take a quantum leap forward, the goal of pragmatists is to make a percentage improvement–incremental, measurable, predictable progress. [..] To market to pragmatists, you must be patient. You need to be conversant with the issues that dominate their particular business. You need to show up at the industry-specific conferences and trade shows they attend.
Re-reading Crossing the Chasm as part of writing this blog post has really helped me square where Rust is – for the most part, I think we are still crossing the chasm, but we are well on our way. I think what we see is a consistent trend now where we have Rust champions who fit the “visionary” profile of early adopters successfully advocating for Rust within companies that fit the pragmatist, early majority profile.
Open source can be a great enabler to cross the chasm…It strikes me that open-source is just an amazing platform for doing this kind of marketing. Unlike a company, we don’t have to do everything ourselves. We have to leverage the fact that open source helps those who help themselves – find those visionary folks in industries that could really benefit from Rust, bring them into the Rust orbit, and then (most important!) support and empower them to adapt Rust to their needs.
…but only if we don’t get too “middle school” about itThis last part may sound obvious, but it’s harder than it sounds. When you’re embedded in open source, it seems like a friendly place where everyone is welcome. But the reality is that it can be a place full of cliques and “oral traditions” that “everybody knows”9. People coming with an idea can get shutdown for using the wrong word. They can readily mistake the, um, “impassioned” comments from a random contributor (or perhaps just a troll…) for the official word from project leadership. It only takes one rude response to turn somebody away.
What Rust needs most is empathySo what will ultimately help Rust the most to succeed? Empathy in Open Source. Let’s get out there, find out where Rust can help people, and make it happen. Exciting times!
-
I am famously bad at accents. My best attempt at posh British sounds more like Apu from the Simpsons. I really wish I could pull off a convincing Greek accent, but sadly no. ↩︎
-
Another of my pearls of wisdom is “there is nothing more permanent than temporary code”. I used to say that back at the startup I worked at after college, but years of experience have only proven it more and more true. ↩︎
-
Russel Cohen and Jess Izen gave a great talk at last year’s RustConf about what our team is doing to help teams decide if Rust is viable for them. But since then another thing having a big impact is AI, which is bringing previously unthinkable projects, like rewriting older systems, within reach. ↩︎
-
I have no idea if there is code in a car’s steering column, for the record. I assume so by now? For power steering or some shit? ↩︎
-
Or am I supposed to call it “tea”? Or maybe “supper”? I can’t get a handle on British mealtimes. ↩︎
-
Ernest is such a joy to be around. He’s quiet, but he’s got a lot of insights if you can convince him to share them. If you get the chance to meet him, take it! If you live in London, go to the London Rust meetup! Find Ernest and introduce yourself. Tell him Niko sent you and that you are supposed to say how great he is and how you want to learn from the wisdom he’s accrued over the years. Then watch him blush. What a doll. ↩︎
-
If you can’t wait, you can read some Zulip discussion here. ↩︎
-
The Battery Packs proposal I want to talk about is similar in some ways to the Rust Platform, but decentralized and generally better in my opinion– but I get ahead of myself! ↩︎
-
Betteridge’s Law of Headlines has it that “Any headline that ends in a question mark can be answered by the word no”. Well, Niko’s law of open-source2 is that “nobody actually knows anything that ’everybody’ knows”. ↩︎
Ludovic Hirlimann: Are mozilla's fork any good?
To answer that question, we first need to understand how complex, writing or maintaining a web browser is.
A "modern" web browser is :
- a network stack,
- and html+[1] parser,
- and image+[2] decoder,
- a javascript[3] interpreter compiler,
- a User's interface,
- integration with the underlying OS[4],
- And all the other things I'm currently forgetting.
Of course, all the above point are interacting with one another in different ways. In order for "the web" to work, standards are developed and then implemented in the different browsers, rendering engines.
In order to "make" the browser, you need engineers to write and maintain the code, which is probably around 30 Million lines of code[5] for Firefox. Once the code is written, it needs to be compiled [6] and tested [6]. This requires machines that run the operating system the browser ships to (As of this day, mozilla officially ships on Linux, Microslop Windows and MacOS X - community builds for *BSD do exists and are maintained). You need engineers to maintain the compile (build) infrastructure.
Once the engineers that are responsible for the releases [7] have decided what codes and features were mature enough, they start assembling the bits of code and like the engineers, build, test and send the results to the people using said web browser.
When I was employed at Mozilla (the company that makes Firefox) around 900+ engineers were tasked with the above and a few more were working on research and development. These engineers are working 5 days a week, 8 hours per day, that's 1872000 hours of engineering brain power spent every year (It's actually less because I have not taken vacations into account) on making Firefox versions. On top of that, you need to add the cost of building and running the test before a new version reaches the end user.
The current browsing landscape looks dark, there are currently 3 choices for rendering engines, KHTML based browsers, blink based ones and gecko based ones. 90+% of the market is dominated by KHTML/blink based browsers. Blink is a fork of KHTML. This leads to less standard work, if the major engine implements a feature and others need to play catchup to stay relevant, this has happened in the 2000s with IE dominating the browser landscape[8], making it difficult to use macOS 9 or X (I'm not even mentioning Linux here :)). This also leads to most web developers using Chrome and once in a while testing with Firefox or even Safari. But if there's a little glitch, they can still ship because of market shares.
Firefox was started back in 1998, when embedding software was not really a thing with all the platform that were to be supported. Firefox is very hard to embed (eg use as a softwrae library and add stuff on top). I know that for a fact because both Camino and Thunderbird are embeding gecko.
In the last few years, Mozilla has been itching the people I connect to, who are very privacy focus and do not see with a good eye what Mozilla does with Firefox. I believe that Mozilla does this in order to stay relevant to normal users. It needs to stay relevant for at least two things :
- Keep the web standards open, so anyone can implement a web browser / web services.
- to have enough traffic to be able to pay all the engineers working on gecko.
Now that, I've explained a few important things, let's answer the question "Are mozilla's fork any good?"
I am biased as I've worked for the company before. But how can a few people, even if they are good and have plenty of free time, be able to cope with what maintaining a fork requires :
- following security patches and porting said patches.
- following development and maintain their branch with changes coming all over the place
- how do they test?
- Are they able to pull something like https://www.youtube.com/watch?app=desktop&v=YQEq5s4SRxY
If you are comfortable with that, then using a fork because Mozilla is pushing stuff you don't want is probably doable. If not, you can always kill those features you don't like using some `about:config` magic.
Now, I've set a tone above that foresees a dark future for open web technologies. What Can you do to keep the web open and with some privacy focus?
- Keep using Mozilla Nightly
- Give servo a try
[1] HTML is interpreted code, that's why it needs to be parsed and then rendered.
[2] In order to draw and image or a photo on a screen, you need to be able to encode it or decode it. Many file formats are available.
[3] Is a computer language that transforms HTML into something that can interact with the person using the web browser. See https://developer.mozilla.org/en-US/docs/Glossary/JavaScript
[4] Operating systems need to the very least know which program to open files with. The OS landscape has changed a lot over the last 25 years. These days you need to support 3 major OS, while in the 2000s you had more systems, IRIX for example. You still have some portions of the Mozilla code base that support these long dead systems.
[5]https://math.answers.com/math-and-arithmetic/How_many_lines_of_code_in_mozillafirefox
[6] Testing implies, testing the code and also having engineers or users using the unfinished product to see that it doesn't regress. Testing Mozilla, is explained at https://ehsanakhgari.org/wp-content/uploads/talks/test-mozilla/
[7] Read a release equals a version. Version 1.5 is a release, as is version 3.0.1.
The Rust Programming Language Blog: Rust debugging survey 2026
We're launching a Rust Debugging Survey.
Various issues with debugging Rust code are often mentioned as one of the biggest challenges that annoy Rust developers. While it is definitely possible to debug Rust code today, there are situations where it does not work well enough, and the quality of debugging support also varies a lot across different debuggers and operating systems.
In order for Rust to have truly stellar debugging support, it should ideally:
- Support (several versions!) of different debuggers (such as GDB, LLDB or CDB) across multiple operating systems.
- Implement debugger visualizers that are able to produce quality presentation of most Rust types.
- Provide first-class support for debugging async code.
- Allow evaluating Rust expressions in the debugger.
Rust is not quite there yet, and it will take a lot of work to reach that level of debugger support. Furthermore, it is also challenging to ensure that debugging Rust code keeps working well, across newly released debugger versions, changes to internal representation of Rust data structures in the standard library and other things that can break the debugging experience.
We already have some plans to start improving debugging support in Rust, but it would also be useful to understand the current debugging struggles of Rust developers. That is why we have prepared the Rust Debugging Survey, which should help us find specific challenges with debugging Rust code.
You can fill out the survey here.
Filling the survey should take you approximately 5 minutes, and the survey is fully anonymous. We will accept submissions until Friday, March 13th, 2026. After the survey ends, we will evaluate the results and post key insights on this blog.
We would like to thank Sam Kellam (@hashcatHitman) who did a lot of great work to prepare this survey.
We invite you to fill the survey, as your responses will help us improve the Rust debugging experience. Thank you!
Mozilla Privacy Blog: Behind the Velvet Rope: The AI Divide on Display at the India AI Impact Summit 2026
TLDR: No one could agree what ‘sovereignty’ means, but (almost) everyone agreed that AI cannot be controlled by a few dominant companies.
This past week, droves of AI experts and enthusiasts descended on New Delhi, bringing their own agendas, priorities, and roles in the debate to the table.
I scored high for my ability to move between cars, rickshaws and foot for transport (mostly thanks to colleagues), but low for being prepared with snacks. So, based on my tightly packed agenda combined with high hunger levels, here’s my read out:
The same script, different reactions
As with any global summit, the host government made the most of having the eyes of the world and deep pockets of AI investors in town. While some press were critical of India seeking deals and investments, it wasn’t notable – or outside of the norm.
What should be notable, and indeed were reflected in the voluntary agreements, were the key themes that drove conversations, including democratisation of AI, access to resources, and the vital role of open source to drive the benefits of AI. These topics were prominent in the Summit sessions and side events throughout the week.
In the name of innovation, regulation has become a faux pas
The EU has become a magnet for criticism given its recent attempts to regulate AI. I’m not going to debate this here, but it’s clear that the EU AI Act (AIA) is being deployed and PRed quite expertly as a cautionary tale. While healthy debate around regulation is absolutely critical, much of the public commentary surrounding the AIA (and not just at this Summit) has been factually incorrect. Interrogate this reality by all means — we live in complex times — but it’s hard not to see invalid criticisms as a strategic PR effort by those who philosophically (and financially) opposed governance. There is certainly plenty to question in the AIA, but the reality is much more nuanced than critics suggest.
What’s more likely to kill a start up: the cost of compliance, or the concentration of market power in the hands of a few dominant players? It’s true that regulation can absolutely create challenges. However, it is also worth looking at whether the greater obstacle is the control a small number of tech companies hold. A buy-out as an exit is great for many start-ups, but if that is now the most hopeful option, it raises important questions about the long-term health and competitiveness of the larger tech ecosystem.
A note of optimism: developing global frameworks on AI may still seem like a pipe dream in today’s macro political climate, but ideas around like-minded powers working together and building trust makes me think that alignment beyond pure voluntary principles may be something we see grow. Frequent references to the Hiroshima Process as a middle ground were notable.
AI eats the world
There were pervasive assumptions that bigger — and then bigger still — is the inevitable direction of AI deployment, with hyperscale seen as the only viable path forward, in terms of inputs needed. However, the magnitude of what’s required to fuel the current LLM-focused market structure met a global majority-focused reality: hyperscaling isn’t sustainable. There were two primary camps at the Summit — the haves and the rest of us — and while the Summit brought them together, the gulf between them continues to grow.
Open source has to win
At the first AI Safety Summit in the UK, the concept of open source AI was vilified as a security risk. At the France AI Action Summit, the consensus began to shift meaningfully. At the India AI Impact Summit, we saw undeniable recognition of the vital role that open source plays in our collective AI future.
With proprietary systems, winning means owning. With open source approaches, winning means we’re not just renting AI from a few companies and countries: we’re working collectively to build, share, secure and inspect AI systems in the name of economic growth and the public interest. Before the Paris Summit, this was a difficult vision to push for, but after New Delhi, it’s clear that open source is on the right side of history. Now, it’s time for governments to build out their own strategies to promote and procure this approach.
Consolidation ≠ Competition
Global South discussions made one message clear: dependency orientated partnerships are not true partnerships and they’re not a long term bet. Many countries are becoming more vocal that they want autonomy of their data and choice in their suppliers to lessen harmful impacts on citizens, and increase their impact to responsibly govern.
That is not today’s reality.
I was, however, encouraged to find that attendees were far less starry-eyed over big tech than at previous Summits. The consensus agreed that it met no one’s definition of sovereignty for a select few companies to own and control AI.
Despite agreement amongst the majority, addressing market concentration remained an elephant in the room. The narrative deployed against regulation became a blanket mantra, applied to anything from AI governance to competition action. However, it fails to address the fact that the AI market is already skewed toward a small number of powerful companies and traditional competition rules that act only after problems arise (and often through long legal processes) are not enough to keep up with fast-paced digital industries.
Some participants were downbeat and questioned if it was too late. The challenge is in demonstrating that it isn’t. There is no single approach. But we know that concentration can be countered with a mix of technical and legal interventions. Options can be sweeping, or lighter touch and surgical in their focus. We are currently seeing is a wave of countries pass, draft, debate and consider new ex ante rules, providing learnings, data and inspiration.
It’s important that we watch this space.
Whose safety are we talking about exactly?
The India AI Impact Summit has been criticised for letting safety discussions fall off the radar. That’s not necessarily true. Instead of focusing on the view that AI is a cause for human annihilation, discussions focused on impacts that we can evidence now: on language, culture, bias, online safety, inclusion, and jobs.
Less headline-grabbing, less killer robots, far more human.
The path forward
It’s difficult to know if these Summits will continue in the long term. There is a lot of fuss, expense, marketing, diplomacy, traffic and word salads involved. However, the opportunity to convene world leaders, businesses, builders, engineers, civil society and academics in one place, for what we are constantly reminded is a transformational technology, feels needed. Tracking progress on voluntary commitments over time might be illustrative. And while many of the top sessions are reserved for the few, witnessing the diverse debates this past week gives me hope that there is an opportunity for the greater voice to shape AI to be open, competitive and built for more than just the bottom line.
The post Behind the Velvet Rope: The AI Divide on Display at the India AI Impact Summit 2026 appeared first on Open Policy & Advocacy.
The Rust Programming Language Blog: Rust participates in Google Summer of Code 2026
We are happy to announce that the Rust Project will again be participating in Google Summer of Code (GSoC) 2026, same as in the previous two years. If you're not eligible or interested in participating in GSoC, then most of this post likely isn't relevant to you; if you are, this should contain some useful information and links.
Google Summer of Code (GSoC) is an annual global program organized by Google that aims to bring new contributors to the world of open-source. The program pairs organizations (such as the Rust Project) with contributors (usually students), with the goal of helping the participants make meaningful open-source contributions under the guidance of experienced mentors.
The organizations that have been accepted into the program have been announced by Google. The GSoC applicants now have several weeks to discuss project ideas with mentors. Later, they will send project proposals for the projects that they found the most interesting. If their project proposal is accepted, they will embark on a several months long journey during which they will try to complete their proposed project under the guidance of an assigned mentor.
We have prepared a list of project ideas that can serve as inspiration for potential GSoC contributors that would like to send a project proposal to the Rust organization. However, applicants can also come up with their own project ideas. You can discuss project ideas or try to find mentors in the #gsoc Zulip stream. We have also prepared a proposal guide that should help you with preparing your project proposals. We would also like to bring your attention to our GSoC AI policy.
You can start discussing the project ideas with Rust Project mentors and maintainers immediately, but you might want to keep the following important dates in mind:
- The project proposal application period starts on March 16, 2026. From that date you can submit project proposals into the GSoC dashboard.
- The project proposal application period ends on March 31, 2026 at 18:00 UTC. Take note of that deadline, as there will be no extensions!
If you are interested in contributing to the Rust Project, we encourage you to check out our project idea list and send us a GSoC project proposal! Of course, you are also free to discuss these projects and/or try to move them forward even if you do not intend to (or cannot) participate in GSoC. We welcome all contributors to Rust, as there is always enough work to do.
Our GSoC contributors were quite successful in the past two years (2024, 2025), so we are excited what this year's GSoC will bring! We hope that participants in the program can improve their skills, but also would love for this to bring new contributors to the Project and increase the awareness of Rust in general. Like last year, we expect to publish blog posts in the future with updates about our participation in the program.
Tarek Ziadé: Running SmolLM-135M in rustnn with flexible inputs
WebNN is emerging as a portable, browser-friendly inference API. But LLMs hit a hard wall: dynamic inputs.
Autoregressive transformers fundamentally mutate state at runtime. KV cache tensors evolve at every step, sequence lengths vary with prompts, and shape expressions flow through operators like Shape, Gather, Concat, Reshape, and Expand.
Today, this does not map cleanly to WebNN’s static-graph constraints.
At step 1, KV cache length is 1. At step 512, KV cache length is 512. That is not a static graph.
Why this mattersIf this is not solved, WebNN stays limited to fixed-shape demos for many LLM use cases.
For real product workloads, people need variable prompt lengths, efficient token-by-token decode, and stable latency as context grows. Without that, local browser LLM UX degrades quickly and teams default back to heavier alternatives.
Dynamic inputs in practiceThis problem is now well documented in the WebNN WG in Issue #883: Support flexible input sizes.
The issue captures exactly what we see in practice:
- Vision models with runtime-determined resolution
- Speech/decoder models where KV cache grows by one token per step
- LLMs with arbitrary prompt lengths and dynamic cache shapes
In other words: modern inference workloads.
The ONNX Runtime workaround (and why it hurts)ONNX Runtime WebNN has had to work around this limitation by routing dynamic-shape parts away from WebNN and into WASM execution paths.
It works, but performance is terrible for autoregressive generation because you bounce between fast backend code and slow fallback code in the hottest part of the loop.
This architecture can make demos pass, but it creates significant performance penalties in real autoregressive workloads.
In preliminary runs, keeping decode on one backend avoids the repeated fallback round-trips that dominate token latency.
So instead of accepting that, we decided to push WebNN support further.
I started this in MaltaI started prototyping this while on vacation in Malta.
What began as a small experiment quickly turned into deep changes across three repositories: converter internals, runtime shape validation, and KV-cache plumbing.
The work happened across:
- webnn-graph: ONNX lowering and dynamic-input metadata support
- rustnn (tarek-flexible-input): dynamic dimensions in graph/runtime + checked execution
- pywebnn: Python demos and loading-from-Hub workflows
I also made sure to surface rustnn through Python (pywebnn) very early.
Most ML engineers live in Python land, and I wanted this work to be reachable by that ecosystem immediately: easier model validation, easier parity checks against transformers, and faster feedback from people who already ship models every day.
What changed in practiceThe key was to support bounded dynamic dimensions end to end.
Why bounded and not fully dynamic? Because many backends still need strong compile-time guarantees for validation, allocation, and kernel planning. Fully unbounded shapes are hard to optimize and hard to validate safely.
Bounded dynamic dimensions are the practical compromise: keep symbolic runtime flexibility, but define a maximum range so memory and execution planning remain deterministic.
This allows the full autoregressive decode loop to stay inside the WebNN backend, without bouncing into slower fallback paths.
This is also better than common alternatives:
- Padding everything to worst-case shapes wastes memory and compute
- Re-exporting one graph per shape explodes complexity
- Falling back dynamic parts to WASM in hot decode loops kills throughput
For example, you can bound a sequence dimension to 2048 tokens: large enough for real prompts, still finite for backend planning and allocation.
In rustnn, tensor dimensions can now be static values or dynamic descriptors with a name and a max size, then checked at runtime:
{ "inputs": { "x": { "dataType": "float32", "shape": [ { "name": "batch", "maxSize": 16 }, 128 ] } } }In webnn-graph, ONNX conversion can preserve unresolved input dynamics while still lowering shape-driving expressions needed by WebNN.
That lets us keep flexibility where possible while still emitting valid WebNN graphs.
SmolLM-135M converted and runningWith flexible inputs supported end to end, SmolLM-135M converts cleanly: no shape rewriting hacks, no per-length exports, no WASM fallback in the decode loop. The artifacts are published here:
Then I built a Python demo in pywebnn/examples/smollm_from_hub.py that:
- downloads model.webnn, model.weights, and manifest from the Hub
- downloads tokenizer.json
- runs token-by-token generation with dynamic KV cache growth
- optionally compares output against transformers
A few extracts from that demo:
The demo defaults to the Hub-hosted WebNN artifacts:
DEFAULT_MODEL_ID = "tarekziade/SmolLM-135M-webnn" model_files = resolve_model_files(args.model_id, force=args.force_download) graph = webnn.MLGraph.load( model_files["graph"], manifest_path=model_files["manifest"], weights_path=model_files["weights"], )past_key_values holds the growing KV-cache tensors returned by the previous step. The decode loop feeds them back on every token:
def run_step(token_id: int, position: int) -> np.ndarray: inputs = { "input_ids": np.array([[token_id]], dtype=np.int64), "position_ids": np.array([[position]], dtype=np.int64), "attention_mask": np.ones((1, position + 1), dtype=np.int64), **past_key_values, } outputs = context.compute(graph, inputs) ...The demo can also run a transformers baseline and fail fast on divergence:
if args.compare_transformers: hf_generated, hf_text, hf_prompt_ids = run_transformers_baseline(...) ... if generated_text != hf_text: print("[ERROR] WebNN and transformers generated different text output") sys.exit(1)Correctness checks against transformers are critical. Performance improvements mean nothing if generation diverges.
Lessons learned- Fully unbounded dynamic shapes are rarely necessary for practical decode loops
- Bounded flexibility captures most real workloads while keeping backends sane
- Python exposure (pywebnn) accelerates model validation and ecosystem feedback
Flexible inputs will likely be important if WebNN is to support real LLM workloads.
Static graphs alone are not enough for modern inference. Bounded flexibility is the pragmatic bridge.
And while this work pushes WebNN forward, we are also giving a lot of love to the TensorRT backend these days, because high-performance local inference matters just as much as API design.
Links- rustnn docs: https://rustnn.github.io/rustnn/
- pywebnn docs: https://rustnn.github.io/pywebnn/
- rustnn WPT conformance dashboard: https://rustnn.github.io/rustnnpt/
Firefox Tooling Announcements: New Deploy of PerfCompare (Feb 17th)
The latest version of PerfCompare is now live! Check out the changelog below to see the updates:
[gmierz]
- Add a link to Bugzilla in the MWU warning banner #981
[kala-moz]
- Add coverage for test version dropdown #983
- Bug 2004156 - Add the mozharness framework as an available option #986.
- Bug 2009257: trigger loader to rerun when setting the test version and framework in url #988
- Set mann-whitney-u as the default test version with replicates enabled by default #999
Our new contributor [moijes12]
- Bug 1919317: Fix the tooltip for Total Runs column #992
- Bug-2003016: Constrain the clickable area of the Home button #996
Thank you for the contributions!
Bugs or feature requests can be filed on Bugzilla. The team can also be found on the #perfcompare channel on Element.
1 post - 1 participant
Thunderbird Blog: Mobile Progress Report: February 2026

The first Mobile Progress Report of 2026 provides a high-level overview to our mobile plans and priorities for the coming year.
AndroidOur primary focus this year revolves around a better user experience and includes a major push to improve quality. We want to make the app stable, reduce our bugs, and speed up our development process. To do this, we have to make some big changes and improvements to the app’s basic structure and database. We’re moving toward modern Android standards, which includes using technologies like Compose and creating a single, consistent design system for our User Interface.
But we don’t want a year of just code fixes; we know we need to add features, especially around messaging & notifications. We’re making sure we deliver features and improve the user experience along the way. It’s a tricky balance between making the app better for users and overhauling the inner workings. We think these changes are worth the investment because they’ll lead to a better app, and ultimately, a better app for everyone. So the focus is better quality and simplifying the code to make us quicker.
Thunderbird has a new product – Thunderbird Pro – and as it comes more online, we plan to connect the Android app to it.
Here are our priorities for the year. P1 is the top focus:
P1
- Get the Android app into a state that’s easier to maintain
- Improve the database structure
- Message List & View improvements
- Unified Account
- Unified Design System (for both iOS and Android)
P2
- HTML signatures
- Looking into JMAP support
P3
- Looking into Exchange support
- Calendar exploration
The main thing we’re trying to do for iOS this year is successfully launch Version 1 of our app. That sounds simple, but it involves building a lot of complicated, low-level foundational things.
This quarter, we’re concentrating on finishing up the IMAP and SMTP pieces, getting our design system established, and building the basic UI so we can start using these pieces. After that, we’ll shift to implementing OAuth. This will stop users from having to use confusing processes, like creating an app token, and let them sign in easily through the standard account import process with a simple User Interface.
Once we have IMAP and OAuth ready, we’ll have the absolute bare minimum for a mail app, allowing users to send and receive email. But there are other features you’d expect in a mail app, like mailboxes, signatures, rich text viewing, attachment handling, and the compose experience. We’ve already made great progress on the underlying functionality, and we have a clear vision of what needs to be implemented to make this successful.
Our key priorities for iOS are:
P1
- Account creation flow
- IMAP support
- Full email writing and reading experience
P2
- JMAP support
- HTML signatures
It’s exciting to see the momentum that the iOS app is gaining and to get a clearer picture of what we need to do for the Android app to simplify things. We are getting farther on fewer, more targeted goals. I look forward to communicating with you over the next few months and share the progress that we are making.
—
Jon Bott (he/him)
Manager, Mobile Apps
The post Mobile Progress Report: February 2026 appeared first on The Thunderbird Blog.
The Mozilla Blog: Heading to India AI Impact Summit, Mozilla leaders call for investment in open source AI as a path to sovereignty

Mozilla is headed to New Delhi, India for the India AI Impact Summit 2026 next week with a message: Open Source is the path to both economic and digital sovereignty. Participating in dozens of events across the weeklong global forum, Mozilla leaders will make the case that a different kind of AI future is possible, and that global action is urgently needed to build a global AI ecosystem firmly grounded in the public interest.
“We’re at a crossroads for AI, where the world can continue to rent from a few big global corporations, or can take back control,” said Mark Surman, president of Mozilla. “To build national resilience and lower costs for their domestic stakeholders, countries should leave India ready to meaningfully invest in open source AI as a transformational solution.”
As part of the India AI Impact Summit 2026, Mozilla is curating three official events that showcase its work to help build a more decentralized AI ecosystem. These include panels on the state of competition in AI, how open source AI can operationalize digital sovereignty, and the launch of a new convenings program aimed at Bollywood artists and filmmakers to explore the future of creativity in the age of AI. Mozilla will also host a community party for open source AI developers and founders.
At the Summit, Mozilla will speak to growing concerns about consolidation in the AI landscape, with just a few large global corporations essentially renting access to AI to the rest of the world. As more powerful AI systems are built and controlled behind closed platforms, users are left with little visibility into how these systems work and almost no ability to shape or govern them. This concentration of control means a small number of companies can decide who gets access to advanced AI, on what terms, and at what cost, with far-reaching consequences for innovation, public institutions, and digital sovereignty.
Mozilla believes this growing concentration of AI control threatens innovation, fair competition and public accountability. To counter this, Mozilla is investing in people, products, and organizations working to build a more open and human-centered AI ecosystem. Open source AI is a key part of this effort, providing practical, real-world infrastructure that allows systems to be inspected, improved locally, and governed in the public interest.
In partnership with G5A, Mozilla Foundation will also launch “The Origin of Thought” at the Summit — a new initiative to explore the intersections of culture and AI. The program will convene Bollywood artists, filmmakers, technologists, and cultural practitioners to help shape a nuanced, multi-faceted understanding of AI’s impact on our lives — not just as a tool but as a potential cultural force. The first taster session, held at The Oddbird Theatre in New Delhi, will feature filmmakers Nikkhil Advani and Shakun Batra.
“Creativity has always been how people make sense of change, long before policy frameworks or product roadmaps catch up. As AI reshapes how culture is made, shared, and remembered, we need spaces that slow the conversation down enough to ask what we’re protecting and why,” said Nabiha Syed, executive director of Mozilla Foundation. “The Origin of Thought brings artists, technologists, and decision-makers together to look beyond efficiency and novelty, and toward the human stakes of this moment. This work reflects our belief that imagination is a critical safeguard, not a luxury. When we center creative voices, we make it possible to build technologies that expand opportunity, dignity, and livelihoods.”
Through its participation at the India AI Impact Summit 2026, Mozilla will reaffirm its commitment to building an AI future that is open, accountable, and shaped by the societies it is meant to serve, and to ensuring that open source AI remains a central pillar of global AI governance and innovation.
“Technology should adapt to humanity, not the other way around,” said Raffi Krikorian, CTO of Mozilla. “Across our entire portfolio, Mozilla is working to decentralize the future of AI — from building new tools for developers to supporting creators to building all levels of the open source AI ecosystem. India, with its incredible community of founders, startups, and developers, knows firsthand that open source AI is where innovation is going next.”
The post Heading to India AI Impact Summit, Mozilla leaders call for investment in open source AI as a path to sovereignty appeared first on The Mozilla Blog.
The Rust Programming Language Blog: crates.io: an update to the malicious crate notification policy
The crates.io team will no longer publish a blog post each time a malicious crate is detected or reported. In the vast majority of cases to date, these notifications have involved crates that have no evidence of real world usage, and we feel that publishing these blog posts is generating noise, rather than signal.
We will always publish a RustSec advisory when a crate is removed for containing malware. You can subscribe to the RustSec advisory RSS feed to receive updates.
Crates that contain malware and are seeing real usage or exploitation will still get both a blog post and a RustSec advisory. We may also notify via additional communication channels (such as social media) if we feel it is warranted.
Recent cratesSince we are announcing this policy change now, here is a retrospective summary of the malicious crates removed since our last blog post and today:
- finch_cli_rust, finch-rst, and sha-rst: the Rust security response working group was notified on December 9th, 2025 by Matthias Zepper of National Genomics Infrastructure Sweden that these crates were attempting to exfiltrate credentials by impersonating the finch and finch_cli crates. Advisories: RUSTSEC-2025-0150, RUSTSEC-2025-0151, RUSTSEC-2025-0152.
- polymarket-clients-sdk: we were notified on February 6th by Socket that this crate was attempting to exfiltrate credentials by impersonating the polymarket-client-sdk crate. Advisory: RUSTSEC-2026-0010.
- polymarket-client-sdks: we were notified on February 13th that this crate was attempting to exfiltrate credentials by impersonating the polymarket-client-sdk crate. Advisory: RUSTSEC-2026-0011.
In all cases, the crates were deleted, the user accounts that published them were immediately disabled, and reports were made to upstream providers as appropriate.
ThanksOnce again, our thanks go to Matthias, Socket, and the reporter of polymarket-client-sdks for their reports. We also want to thank Dirkjan Ochtman from the secure code working group, Emily Albini from the security response working group, and Walter Pearce from the Rust Foundation for aiding in the response.