
Mozilla stopt met Pocket-app en Fakespot om zich op Firefox te focussen - TechPulse
Het einde van een oudgediende app - iCulture
Software-update: Mozilla Thunderbird 138.0.2 - Computer - Downloads - Tweakers
Software-update: Mozilla Firefox 138.0.4 - Computer - Downloads - Tweakers
Software-update: Mozilla Thunderbird 138.0.1 - Computer - Downloads - Tweakers
Software-update: Mozilla Firefox 138.0.3 - Computer - Downloads - Tweakers
Mozilla’s CEO discusses testimony in U.S. v. Google search case
Today, Mozilla Chief Financial Officer, Eric Muhlheim, testified in the U.S. v. Google LLC search trial, highlighting the potential impacts this case could have on small and independent browsers, and the overall ecosystem.
There are a few key themes of Muhlheim’s testimony that we’ll expound on:
Mozilla’s search options are based on user choiceFirefox users view Google as the best quality search engine. Mozilla experienced this firsthand when we switched the Firefox browser’s default search engine from Google to Yahoo between 2014 and 2017 in an effort to support search competition. Firefox users found Yahoo’s search quality lacking and some switched to Google search while others left the Firefox browser altogether.
Firefox offers its users greater and more easily accessible search engine choice than any major browser. From providing search engine shortcuts, to easy default settings and a range of options in the address bar, alternative search engines are readily available within Firefox. Put simply, our long-standing search strategy has been to evaluate and select the best search experience region by region, enabling choice for Firefox users with more than 50 search providers across more than 90 locales. We make sure our agreements do not make Google an exclusive search provider on Firefox or impede our ability to promote choice.
The breaking pointIt’s no secret that search revenue accounts for a large portion of Mozilla’s annual revenue. Firefox is an independent browser — we don’t have our own OS, devices, or app store. Without this revenue, Mozilla and other small, independent browsers may be forced to scale back operations and cut support for critical projects like Gecko, the only remaining browser engine competing with Google’s Chromium and Apple’s WebKit.
Innovation, privacy and user choice can only thrive when browser engines compete. Without that, there’s no push to make the web faster, safer, or more inclusive. If we lose or weaken Gecko, the web will be optimized for commercial business models and priorities, not the values that Mozilla champions for the web such as privacy, accessibility and user choice. The open web only stays open if websites, apps, and content interoperate and work everywhere.
Truly improving competition and choice cannot solve one problem by creating another.
The path forwardFollowing the testimony, Laura Chambers, CEO of Mozilla, emphasized what we’d like to see coming out of the trial by stating: “This case will shape the competitive landscape of the internet for years to come, and any remedy must strengthen, rather than weaken, the independent alternatives that people rely on for privacy, innovation, and choice.
Smaller, independent browsers, like Firefox, rely on monetization through search partnerships to sustain our work and invest in user-focused innovation. Without these partnerships, we’d face serious constraints—limiting not just our ability to grow but also the availability to provide a non-profit-backed alternative to Chrome, Edge, and Safari.
This case is also about user choice. Mozilla’s approach to search is built around giving people options. Time and again, we’ve seen people leave our browser when forced to use a search engine they don’t prefer. Without search partnerships, independent browsers — like Mozilla’s Firefox browser and Gecko browser engine — would face severe constraints.
We recognize the importance of improving search competition. However, doing so shouldn’t come at the cost of browser competition. We believe the court should ensure that small and independent browsers are not harmed in any final remedies. Without this, we risk trading one monopoly for another, and the vibrant, people-first web we’ve spent decades fighting for could begin to fade.”
The post Mozilla’s CEO discusses testimony in U.S. v. Google search case appeared first on The Mozilla Blog.
An NYC culture reporter on YouTube’s influence and the tab that got away
 Adlan Jackson is a writer, editor and worker-owner at Hell Gate, a New York City news publication founded as a journalist-run cooperative.
Adlan Jackson is a writer, editor and worker-owner at Hell Gate, a New York City news publication founded as a journalist-run cooperative.
Here at Mozilla, we are the first to admit the internet isn’t perfect, but we know the internet is pretty darn magical. The internet opens up doors and opportunities, allows for human connection, and lets everyone find where they belong — their corners of the internet. We all have an internet story worth sharing. In My Corner Of The Internet, we talk with people about the online spaces they can’t get enough of, the sites and forums that shaped them, and how they would design their own corner of the web.
We caught up with Adlan Jackson, the culture reporter and editor at Hell Gate, a reader-supported New York City news site owned and run by journalists. He talks about YouTube’s cultural influence, the browser tab he shouldn’t have closed and joining his first online forum at age 11 (with parental permission).
What is your favorite corner of the internet?I’m a millennial, so I still think YouTube is maybe the most important and underrated social network. I feel like so much culture runs downstream from YouTube.
I’ve got a few different niches. One is “A Song of Ice and Fire,” the “Game of Thrones” book series. I’m into the deep lore and theory videos, especially the esoteric stuff decoding symbolism. That’s my “chew through some hours” zone.
I also love watching performance videos. The YouTube of the late 2000s and early 2010s had this thriving music community. People would post covers, concert footage, TV performances — all of it. I feel like I developed my entire music taste and sensibility from those videos. That scene has kind of dropped off in the Instagram era, which is a shame, because Instagram just doesn’t archive like YouTube does.
There are still some people out there doing it, though. There’s someone on YouTube right now who’s super active in New York — they go to a ton of indie shows and tape them. I’ve actually been DMing them to ask for an interview, but they haven’t responded.
And yeah, I read the comments. YouTube comments on music videos are famously sentimental and mostly pretty positive. But I like the arguments, too. There’s a lot of generational overlap in the YouTube community, so you’ll see these debates play out that don’t really happen on other platforms.
What is an internet deep dive that you can’t wait to jump back into?I’ve been really trying to understand online gambling.
I’m not a sports person, so the whole legalization and mainstreaming of sports betting completely passed me by. But it feels like it’s everywhere now — so pervasive that I feel like I’m missing out by not understanding the culture, how it works and why it seems to have hooked people so universally. Lately, I’ve been trying to spend more time in online gambling communities to figure it out.
What is the one tab you always regret closing?I kind of have this eternal regret that there was some tab I closed that I shouldn’t have — and if I hadn’t, my life would be completely different and better. I have no idea what it was, but I’m sure it mattered.
I used to have hundreds of tabs open all the time. I’ve recently resolved to stop doing that and just close everything out regularly. But back then, I definitely felt like there were essays and Substack posts that were going to lead me to my next big story — and now they’re just gone.
What can you not stop talking about on the internet right now?I try to avoid posting [on social media] too much. I used to tweet a lot. Now, in my capacity as a blogger at Hell Gate, I can’t stop talking about the local music scene.
What was the first online community you engaged with?It was probably this MMO RPG I used to play called “MapleStory” — a Korean side-scrolling, action-adventure, anime-style RPG. There was a forum called sleepywood.net. Sleepywood was a town in MapleStory, so that’s what the website was named after.
I was in there at 11 years old. I remember signing up for the forum — it was just an old style web forum. You had to be 13 or older, and I wasn’t. So I asked my mom, “Can you give me permission to be on this forum?” She wrote a thing, and they let me on.
What’s funny is, I could have just made it up. But I specifically remember that I didn’t. I really got my mom’s permission.
If you could create your own corner of the internet, what would it look like?I think it would be a place where people feel empowered to create on their own terms. A space where independent media is thriving, and where people are more motivated to pay for work created by people they personally value — not by large conglomerates.
So, someone who skips a Netflix subscription but pays for their friend’s blog. Or someone who doesn’t have Amazon Prime, but subscribes to a local newspaper.
What articles and/or videos are you waiting to read/watch right now?Let me look. What do I have opened? The first thing on my YouTube is a Lord of the Rings lore video by In Deep Geek, which is a channel I follow pretty regularly. It’s about the Dead Men of Dunharrow, the ghost warriors who join Aragorn at the gates of Mordor. I’ll probably watch that later today.
If the internet were designed to strengthen local news, what would that look like? Who should be responsible for making that happen?I think the government should give money to local news outlets because we’re an important part of civil society. Mostly, I think the government should support local media. But it’s also nice when people really believe in it, too.
As for tech companies — it depends on the company. Some shouldn’t play a role at all. But unconditional cash? That would be great. Cash with no conditions attached.
Adlan Jackson is a writer, editor and worker-owner at Hell Gate, a New York City news publication founded as a journalist-run cooperative. He joined the team in 2023 to focus on arts and culture coverage — a beat Hell Gate has always embraced, but Adlan is the first staffer dedicated specifically to it. He covers what’s happening around the city and keeps readers up to date on the local art scene. His work has also appeared on Pitchfork, the New York Times Magazine and The New Yorker.
The post An NYC culture reporter on YouTube’s influence and the tab that got away appeared first on The Mozilla Blog.
Tackle tab overload with Firefox Tab Groups

Open a web browser and you step into a garden of forking paths — where news, messages, memes, work, learning and cat videos all compete for your attention. Every click sprouts another tab. Before you know it, your author has opened 68,000 tabs in one year alone, while some people manage to keep 7,000 tabs open for years. Firefox Tab Groups is designed to help you organize tabs, offering a better way to browse.
(Eager to try it out? Jump to getting started with Tab Groups.)
How too many tabs drain your focus and timeResearch shows that tab overload can start with just five to eight tabs open. And when you factor in how many tabs we open each day, it’s clear we need better tools to stay organized.
If you use a browser at work or school, this scenario may sound familiar: You are writing in one tab when you realize you need information from another. You go on a tab hunt, scanning the tiny icons in your tab bar, skimming the first few letters of each tab title, navigating from window to window, searching for that elusive document or presentation.
You finally find it. Victory is mine! But before you can celebrate, you have to find your way back to that first tab. And so the cycle of tab re-finding begins anew.
Or you glance at your browser and feel overwhelmed. So many semi-random tabs open that the only solution seems to be to declare tab bankruptcy, close everything and start over.
These are all symptoms of information overload, the condition of having more information than you need to make a decision or complete a task efficiently. It is one of the defining challenges of our digital age. As former Google CEO Eric Schmidt once said, “There were 5 exabytes of information created between the dawn of civilization and 2003, but that much information is now created every two days.” Whether or not you believe the numbers, the feeling is real: We are surrounded by more information, more distractions and more tabs.
Firefox Tab Groups are designed to give you more control, whether you manage thousands of tabs or prefer to keep just a few open.
How to organize your tabs with Tab Groups Firefox tab groups now availableTab Groups add a layer of color-coded organization to your browser, making it easier to keep related tabs together. You can create groups for topics, projects or recurring tasks — like the news sites you read daily, ideas for a new woodworking hobby or research for an upcoming trip to Thailand.
Ideas for organizing your tabs:
- By urgency: Tabs for tasks you need to finish soon, like a “Friday to-do” list
- By frequency: Sites you visit daily, such as news or email
- By topic: Tabs for different courses, hobbies, or areas of interest
- By project: Resources and tools collected for an important project
- By type: Similar tabs grouped together, like PDFs or pages from the same site
Once you have a few groups set up, it becomes much faster to find your tabs and switch between tasks.
Getting started with Tab GroupsStarting with Firefox Version 138, available April 29, you can manage your tabs more easily with the new Tab Groups feature.
Here’s how to get started:
- Create a group: drag a tab on top of another, pause and drop

- Name and color the group (name is optional)

- Add or remove tabs from a group by dragging tabs in and out of a group
- Manage the group by right-clicking the group label. From there you can:
- Create a new tab in the group
- Move group to new window
- Save and close the group to free up space on the tab bar
- Ungroup tabs
- Delete the group

- Reposition a group on the tab bar by dragging it
- Expand or collapse a group when you single-click the group label

- Retrieve a group. Browse all groups in the List all tabs menu (a downward caret in the top right corner of the tab bar)
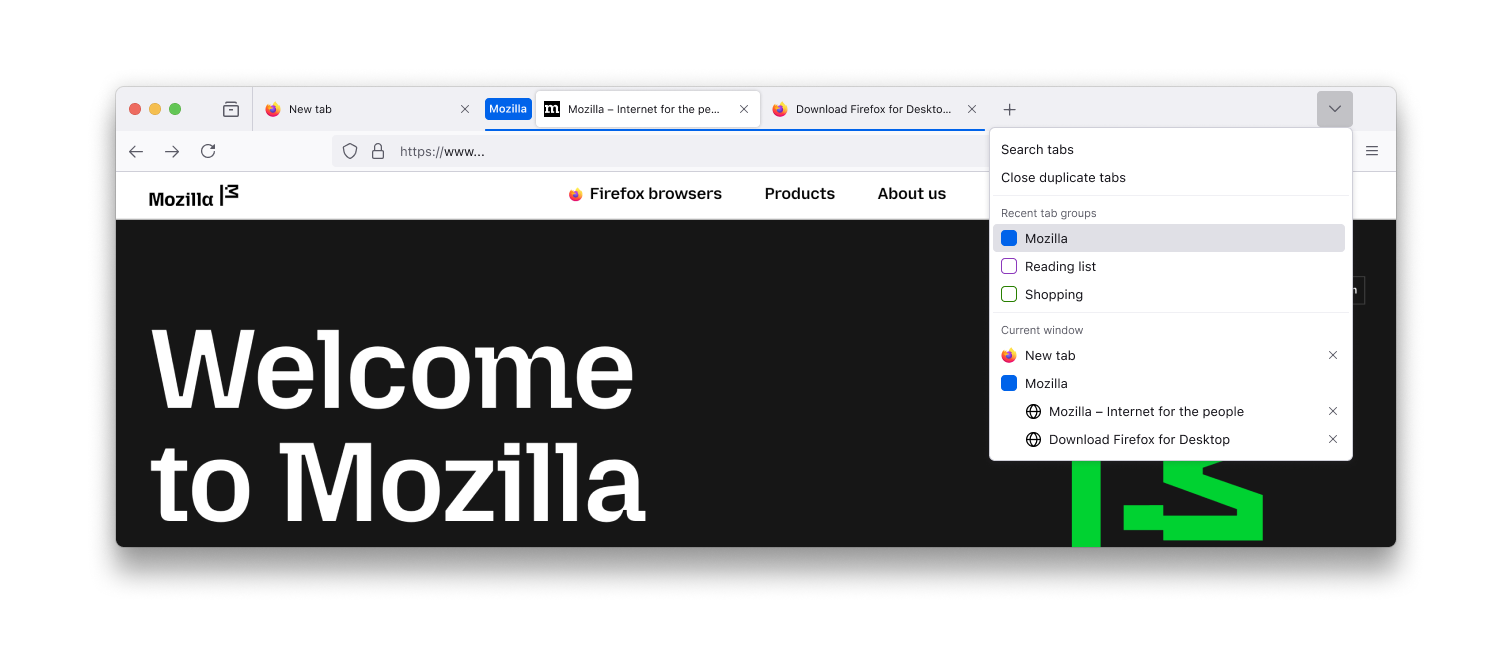
See our support page for Firefox Tab Groups for more details.
Other ways to use Tab GroupsIf you manage a lot of tabs, you might want to explore Firefox’s new Vertical Tabs mode. With vertical tabs, you can expand or collapse the amount of the tab title you see, which can make it easier to re-find the tab you need.
You can also combine Tab Groups with add-ons to manage your tabs even more efficiently. If you’ve ever closed a tab and wished you could get it back, Firefox has plenty of add-ons to help you recover and organize your tabs.
New APIs (tools that help programs work together) are on the way, giving add-on developers even more ways to manage tabs and groups. If you’re using add-ons with Tab Groups today, just keep in mind that some add-ons may move tabs into or out of groups, or close grouped tabs.
Making tab management even smarter with AITab Groups make it easier to stay organized, but even with better tools, tab management can still be a chore — especially as your habits and needs change.
To make it even easier over time, we’re exploring new AI-powered tools for organizing tabs by topic. You can try an early prototype today with on-device AI in Firefox Nightly, our next-generation browser for testing and development.
Shape what’s next for managing tabsTry out Tab Groups in Firefox and tell us what you think in our community forum, Mozilla Connect.
If you want a sneak peek at what’s next, you can also test an early AI-powered prototype in Firefox Nightly and look for the “Suggest more of my tabs” button when creating a group. And unlike other browsers, with Firefox you can always feel confident that no one sees your tabs except you, even if you organize them with AI.
The web will keep growing and changing. With Firefox, you stay in control of your tabs and the path you choose to take.
 Get the browser that puts your privacy first — and always has Download Firefox
Get the browser that puts your privacy first — and always has Download Firefox
The post Tackle tab overload with Firefox Tab Groups appeared first on The Mozilla Blog.
Mozilla, EleutherAI launch toolkits to help AI builders create open datasets

Easy-to-follow guides on how to transcribe audio files into text using privacy friendly tools and how to convert different documents into a singular format. Watch the live demo here.
As concerns around AI transparency grow, datasets remain one of the least visible and least standardized parts of the pipeline. Many are assembled behind closed doors, with little documentation or clarity around sourcing. Independent developers are often left without the infrastructure or tools needed to do things differently.
Mozilla and EleutherAI’s year-long collaboration aims to change that. They’re releasing two toolkits that help developers build large-scale datasets from scratch—whether that means extracting content from PDFs, structuring web archives, or simply documenting what they’re using in a clear and reusable way.
These toolkits help developers get started with creating open datasets. The code and demos will be available on the Mozilla.ai Blueprints hub, a platform that helps developers prototype with open-source AI using out of the box workflows.
Toolkit 1: Transcribing Audio Files with Open-Source Whisper Models
This Blueprint guides developers through transcribing audio using open-source Whisper models via Speaches, a self-hosted server similar to the OpenAI Whisper API. Designed for local use, this privacy focused setup offers a secure alternative to commercial APIs, making it ideal for handling sensitive or private audio data. Inspired by real-world use cases, the toolkit features an easy to follow setup using either Docker or the CLI.
Toolkit 2: Converting Unstructured Documents into Markdown Format
This toolkit helps developers convert diverse document formats (PDFs, DOCX, HTML, etc.) into Markdown using Docling, a command-line tool with powerful Optical Character Recognition and image-handling capabilities. Ideal for building open-text datasets for use in downstream applications, this toolkit emphasizes accessibility and versatility, including batch-processing capabilities.
Mozilla and EleutherAI’s partnership included an AI dataset convening, which brought together 30 leading scholars and practitioners from prominent open-source AI startups, nonprofit AI labs, and civil society organizations to discuss emerging practices for a new focus within the open LLM community, culminating with the publication of the research paper: “Towards Best Practices for Open Datasets for LLM Training”. The new toolkits are a final milestone in this partnership and are a resource to help builders action the best practices previously shared.
“As AI development continues to move at warp speed, we must ask ourselves ‘how can we responsibly curate and govern data so that the AI ecosystem becomes more equitable and transparent’ says Ayah Bdeir, Mozilla Foundation Senior Advisor, AI Strategy “Today’s open data ecosystem depends on the community sharing its expertise and our partnership with EleutherAI is part of our commitment to support incredible builders who are iterating and experimenting on the front lines of open source AI.
Currently, the threat of litigation is often cited as a reason for minimizing dataset transparency, hindering transparency and innovation. Building open access data is the antidote. Building a future of responsibly curated, openly licensed datasets requires collaboration across legal, technical, and policy fields, along with investments in standards and digitization. In short, open-access data can address many AI challenges, but creating it is difficult. The toolkits from EleutherAI and Mozilla are a crucial step in making this process easier.
“Creating high-quality, large-scale datasets is one of the biggest bottlenecks in AI development,” says Stella Biderman, Executive Director, EleutherAI. “ Developers—especially those outside of major tech firms—often resort to whatever data is easiest to access, even when more valuable sources are trapped in PDFs or audio. These tools make it easier for open-source developers to unlock that data and build stronger, more diverse datasets.”
Update: On April 28, EleutherAI and Mozilla hosted an event to demo the two blueprints. Watch the demo here.
The post Mozilla, EleutherAI launch toolkits to help AI builders create open datasets appeared first on The Mozilla Blog.
Ads performance, re-imagined. Now in beta: Anonym Private Audiences.

Together, Mozilla and Anonym are proving that effective advertising doesn’t have to come at the cost of user privacy. It’s possible to deliver both — and we’re building the tools to show the industry how.
Today, we’re unveiling Anonym Private Audiences: a confidential computing solution allowing advertisers to securely build new audiences and boost campaign results.
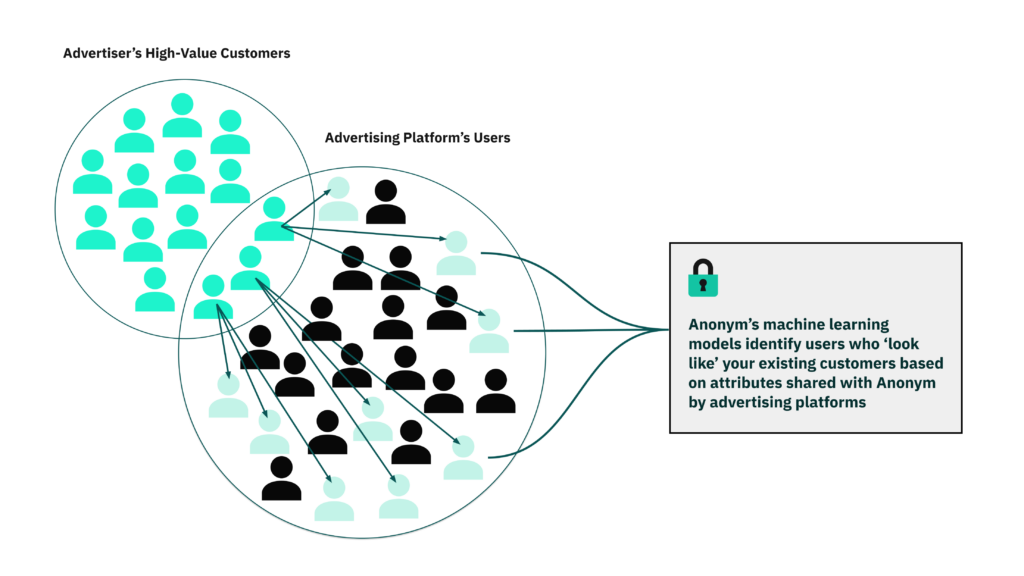
Powered by advanced privacy-preserving machine learning, Anonym Private Audiences enables advertisers and platforms to work together using first-party data to create targeted audiences without ever handing their users’ information to one another. Brands can discover and engage look-alike communities — reaching new high value customers — without sending, or exposing their customers’ data to ad platforms. As the evolving advertising landscape makes third-party data less viable, Private Audiences supports privacy while enabling the performance advertisers have come to expect.
Private Audiences employs differential privacy and secure computation to minimize the sharing of data commonly passed between advertisers and ad networks. It operates separately, and is not integrated with, our flagship Firefox browser.
Why advertisers are turning to Private AudiencesAdvertisers today are facing a difficult challenge: how to grow their business without breaking the trust of the people they’re trying to reach. Private Audiences was built to meet that moment — helping teams use the data they already have to find new high-value customers, without giving up data control along the way.
Early adopters are already seeing meaningful gains, with campaign performance improving an average of 30% compared to traditional broad targeting. And the reasons why it’s resonating are relevant to any brand looking to grow smarter and more sustainably:
- Find the right people, not just more people. Predictive machine learning helps advertisers reach new audiences that look and behave like their best customers — improving efficiency without ramping up spend.
- Keep trust intact. In sectors where privacy expectations are highest, early adopters are showing that it’s possible to respect user’s privacy and still drive results.
- Use what you already know. Private Audiences works with the tools teams already rely on. Audiences show up in platform-native interfaces, so there’s nothing new to learn or configure.
- Stay ahead of shifting standards. Private Audiences is built on privacy-first architecture — helping brands keep pace with evolving norms, expectations, and technical requirements.
In most audience-building workflows today, advertisers integrate directly with ad platforms to share customer data— whether through raw file uploads or automated server-to-server transfers. The platform then uses that data to build ‘look-alike’ audiences or, in some cases, retarget those same individuals directly. Anonym’s approach enables businesses to retain full control over their user data and employ gold standard protections, which are particularly important in privacy-sensitive industries and regions.
Private Audiences takes a fundamentally different approachInstead of sharing data directly with platforms, brands securely upload a list of high-value customers using a simple drag-and-drop interface. That data is encrypted and processed inside Anonym’s Trusted Execution Environment (TEE), where audience modeling happens in isolation. No data is exposed — not to Anonym, and not to the platform. Anonym trains the model, ranks eligible audiences based on likely performance, and returns a ready-to-use audience segment. Anonym’s ad platform partners only learn which of their existing users to include in the audience – they receive no new personal information or audience attributes. When the process is finished, the TEE is wiped clean.
The result: strong performance, without giving up data control or compromising on privacy.
 Breakthrough performance and privacy capabilities with Private Audiences, and more
Breakthrough performance and privacy capabilities with Private Audiences, and more
Private Audiences joins the ranks of Anonym’s other solutions: Private Attribution, which enables accurate view-through attribution without user tracking, and Private Lift, which helps advertisers understand incrementality without exposing identities. Together, Anonym’s tools represent a new foundation for digital advertising trust — a solution portfolio built on transparency, accountability, and respect for the people it reaches.
Because trust isn’t optional — it’s foundationalMozilla has always believed privacy is a fundamental human right, and we will continue our relentless focus on designing and delivering products and services to protect it. Advertising performance — as much as privacy — is a foundational part of this journey.
Anonym Private Audiences is currently in closed beta, supporting early-use cases where privacy matters most. We’re excited to partner with all advertisers seeking a better way to build high-performing audiences without compromising your customers’ trust.
For a deeper dive or beta participation details, get in touch with us here.
 Performance, powered by privacy Learn more about Anonym
Performance, powered by privacy Learn more about Anonym
The post Ads performance, re-imagined. Now in beta: Anonym Private Audiences. appeared first on The Mozilla Blog.
Exploring on-device AI link previews in Firefox
Ever opened a bunch of tabs only to realize none of them have what you need? Or felt like you’re missing something valuable in a maze of hyperlinks? In Firefox Labs 138, we introduced an optional experimental feature to enhance your browsing experience by showing a quick snapshot of what’s behind a link before you open it. This post provides some technical details of this early exploration for the community to help shape this feature and set the stage for deeper discussions into specific areas like AI models.
InteractionTo activate a Link Preview, hover over a link and press Shift (⇧) plus Alt (Option ⌥ on macOS), and a card appears including the title, description, image, reading time, and 3 key points generated by an on-device language model. This is built on top of the Firefox behavior to show the URL when over a link, so it also works when links are focused with the keyboard. We picked this keyboard shortcut to try avoiding conflicts with common shortcuts, e.g., opening tabs or Windows menus. Let us know: do you prefer some keyboard shortcut or potentially other triggers like long press, context menu, or maybe hover with delay?
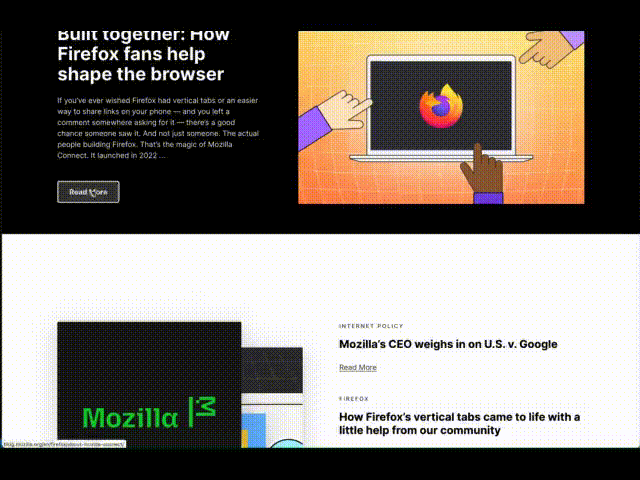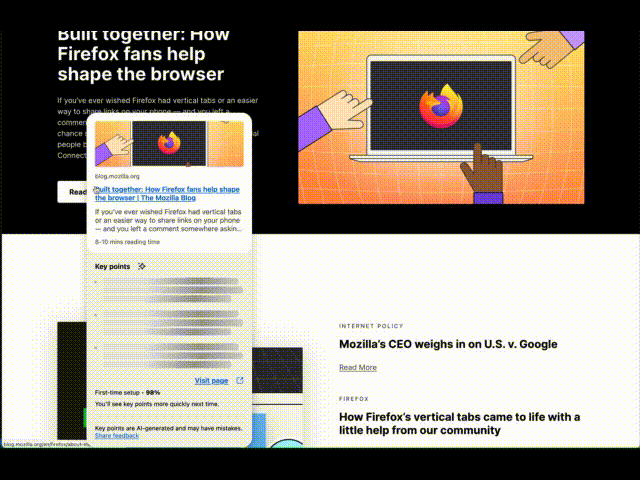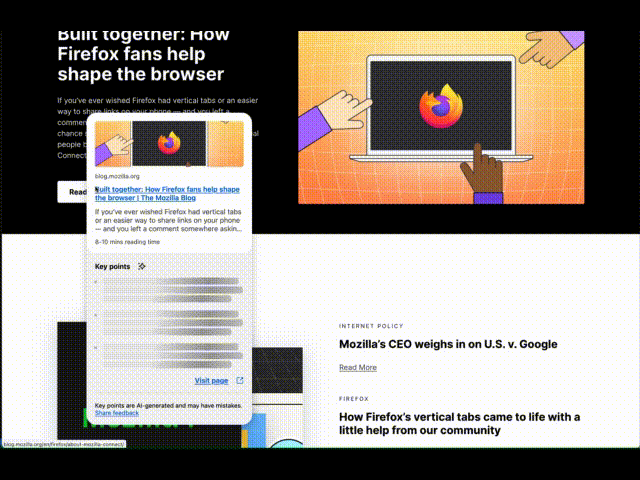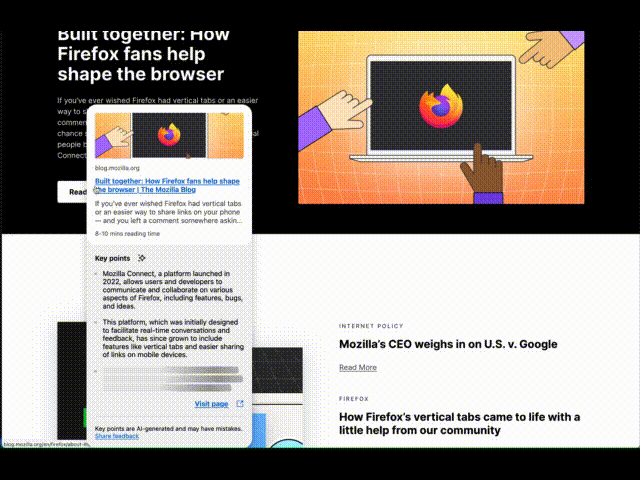
The card appears in a panel separate from the page, allowing it to extend past the edges of the window. This helps us position the link within the card near your mouse cursor, making it convenient to visit the previewed page, while also reinforcing that this comes from Firefox and not the page. We’re also exploring the possibility of making it part of the page, allowing them to scroll together or more separately, such as a persistent space to gather multiple previews for cross-referencing or subsequent actions. Let us know: which approaches better support your browsing workflows?
Page fetching and extractionThis initial implementation uses credentialless HTTPS requests to retrieve a page’s HTML and parses it without actually loading the page or or executing scripts. While we don’t currently send cookies, we do send a custom x-firefox-ai header allowing website authors to potentially decide what content can be previewed. Let us know: would you want previews of content requiring login, perhaps with a risk of accidentally changing related logged in state?
With the parsed page, we look for metadata, such as Open Graph tags, which are commonly used for social media link sharing, to display the title, description, and image. We also reuse Firefox’s Reader View capabilities for extracting reading time and the main article content to generate key points. Improvements to page parsing capabilities can enhance both Reader View and Link Previews. Let us know: which sites you find the feature useful and on which it might pull the wrong information.
Key points, locally generatedTo ensure user privacy, we run inference on-device with Reader View’s content. This is currently powered by wllama (WebAssembly llama.cpp) with SmolLM2-360M from HuggingFace, chosen based on our evaluation of performance, relevance, consistency, etc. Testing so far shows most people can see the first key point within 4 seconds and each additional point within a second, so let us know: how that feels for you and if you’d want it faster or smarter.
There are various optimizations to speed things up, such as downloading the AI model (369MB) when you first enable the feature in Firefox Labs, as well as limiting how much content is provided to the model to match up with the intent of a preview. We also use pre-processing and post-processing heuristics that are English-focused, but some in the community have already configured the language limiting pref from “en” and provided helpful feedback that this model can work for other languages too.
Next stepsWe’re actively working on improving support for multiple languages, key points quality and length, and general polish to the feature capability and user experience as well as exploring how to bring this to Android. We invite you to try Link Preview and look forward to your feedback in enhancing how Firefox helps users accomplish more on the web. You can also chat with us on AI@Mozilla discord #firefox-ai.
The post Exploring on-device AI link previews in Firefox appeared first on The Mozilla Blog.
Mitchell Baker: Global AI Summit on Africa
I’m on my way to the Global AI Summit on Africa in Kigali on April 3 and 4, thanks to an invitation from the Ministry organizing the event. I’ll be speaking, but mostly listening and learning and hopefully connecting with people who are drawn to approaches that are open and creative. If you know someone at this event I should meet, please do let me know.
I’m scheduled to be the main guest at the Fireside Chat on April 1. I’ll also be participating in the panel “Innovating for a Healthier Future.” This panel topic combines open source and health with new AI developments. I’ve been working with OpenMRS (as a board member) on open source electronic medical records for better outcomes for some years. I’m eager to dive into the impacts of AI on this work with the broad set of experts at the Summit.
After the Summit, I’ll spend a few days in Nairobi. I’ll say more about the Summit shortly.
Open-source AI is hard. Blueprints can help!
“I spend 8 hours per week trying to keep up to date, it’s overwhelming!”
“Integrating new libraries is difficult. They’re either poorly maintained or updated in ways that break compatibility.”
“I want to be able to experiment quickly, without relying on APIs for closed-source models.”
These were just a few of the challenges we heard from developers during months of interviews. Today, we’re excited to introduce Blueprints and the Blueprints Hub!
Meet Mozilla.ai BlueprintsThe Blueprints Hub is designed to cut through the clutter of clunky tool integration and outdated resources, so you can focus on building, not troubleshooting. It’s a showcase for the best of the open-source builder community.
What are Blueprints?Blueprints are your go-to, customizable workflows that enable you to prototype AI applications with trusted open-source tools. Each Blueprint tackles a real-world challenge, giving you a robust foundation to work from:
- Open-source power: Fully hosted on GitHub and built with the community.
- Ready out-of-the-box: Get started instantly with accessible setup options.
- Customizable and extendable: Use it as-is or extend it to fit your own needs.
- Consistent and templatized: Every Blueprint follows a core template to keep your workflow smooth.
- Community-driven: Contribute, collaborate, and be part of something bigger.
Our launch lineup
Kick off your journey with these five practical Blueprints:
- Document-to-Podcast: Turn your text into lively, multi-voice audio clips with minimal fuss.
- Structured Question Answering: Extract answers from structured documents with a simple workflow.
- Finetuning Speech-to-text: Fine-tune speech models locally for multiple languages or your own dataset.
- OpenStreetMap AI Helper: Use computer vision to detect and map features on OpenStreetMap, with Human Verification.
- Finetuning an LLM with Federated AI: Collaboratively fine-tune models across data owners without sharing raw data.
- Build your own Timeline Algorithm: Visualize, search, and re-rank social posts using AI without data leaving your computer.
Our new Hub is built for ease and exploration:
- Instant demos: Play around with Blueprints live in the hosted demo. No installation required.
- Video walkthroughs: Follow our video guides for a step-by-step introduction
- Technical insights: Understand the technical choices made during development of each Blueprint
- Practical use-cases: See how other developers are customizing and extending these Blueprints for their needs.
- Join our community: Share your blueprints, learn from fellow innovators, and help expand the hub.
Join us and see how Mozilla.ai Blueprints Hub can speed up your development and spark your creativity. Visit our website now to explore, experiment, and become part of our vibrant community. Your next great idea is just a click away!
 Ready to transform your AI projects? Explore the Blueprints Hub
Ready to transform your AI projects? Explore the Blueprints Hub
The post Open-source AI is hard. Blueprints can help! appeared first on The Mozilla Blog.
Reaching readers, one TikTok at a time
 Sanibel Lazar is using TikTok to break beyond traditional book promotion.
Sanibel Lazar is using TikTok to break beyond traditional book promotion.
Spoiler: The internet’s not finished. Welcome to “Web in Progress,” a series celebrating the internet as a space you can shape, not just scroll through. Just as Firefox empowers you to take charge of your online experience, this series highlights how individuals and communities are shaping an internet that truly serves their needs.
In this installment, see how a debut novelist is using TikTok to break beyond traditional book promotion. By focusing on niche interests, she found new ways to connect with readers who might never have picked up her book. Her experience is a testament to how digital platforms can open unexpected doors.
Before I started promoting my debut novel, “To Have and Have More,” I hadn’t posted on any social media platform since 2015. Creating content wasn’t in my plan — until I realized it was the most practical way to get my book noticed. Working with a brand-new press meant I had to carve out my own opportunities. Social media was a means to feel like I was in the driver’s seat as my book went out into the world.
Instead of feeling overwhelmed by the need to promote my book, I leaned into what I could control. I started creating videos on TikTok, not as part of BookTok, but tailored to themes from my book like class, privilege and wealth. They led me to unexpected audiences. I’ve ended up on PrivilegeTok, WealthTok, StatusSymbolTok and even QuietLuxuryTok — places where I stand out as the only person talking about a novel. My videos are a way to access audiences who might not otherwise pick up a book.
When one of my videos hit a couple hundred thousand views, I checked my Amazon ranking and watched my book climb. Social media has also brought me opportunities I didn’t anticipate. Rather than chasing podcast invites or op-eds, I’ve been getting invitations to do readings and guest spots (it’s thanks to social media that I got tapped to write this article) — all because people discovered me through my content.

I’m not on TikTok to recommend books or talk about author life; instead I riff on social etiquette, classism, and luxury brands. My strategy isn’t about jumping on trend bandwagons but about getting people interested in my book. I call this approach “Oblique Content,” inspired by perfume ads that sell a mood or idea rather than focusing on product specs. In my videos, I talk about everything from toxic wealth to throwback millennial fashion trends — and I plug my book for ten seconds at the end.
I got a DM recently from a follower who said she was shocked to see a certain high-end brand at TJMaxx and thought of me. That message was a small but significant sign: My content was resonating. People were connecting my name and voice with the themes of my book.
For creatives, finding success on social media isn’t as simple as racking up views. You want your followers to be interested in your body of work and your ideas — not just your ability to “stop the scroll.” My advice? Experiment widely and don’t pigeonhole yourself in the conventions of your genre. And don’t get sidetracked scrolling for inspiration; focus on creating.
Sanibel Lazar is a writer based in New York City. She earned her MFA from The New School and her BA in Classical Studies from the University of Pennsylvania. Her debut novel, “To Have and Have More,” will be published in April 2025. Sanibel’s work has appeared in New York Magazine, ELLE, Air Mail, Literary Hub and more.
The post Reaching readers, one TikTok at a time appeared first on The Mozilla Blog.
Misinformation in the age of AI: It’s in the details (like extra fingers)
As you scroll through social media, the posts blend together: a heroic cat, a shocking statistic, a breaking news clip. But in a world where AI blurs the line between fact and fiction, how do you tell what’s real from what’s misinformation?
The short answer: Most of the time, you can’t. Generative AI tools have made it faster, cheaper, and easier to create convincing fakes, flooding our feeds with AI-generated content. But here’s what you can do – learn to spot the signs of misinformation.
What should I think about when trying to detect AI?Just looking out for obvious AI will mean missing a lot of it. Retrain your brain to assess social media on a framework similar to the ones used by AI-misinformation researchers. Consider who’s behind the post, whether the content makes sense, how it’s written, the emotions it evokes and any signs of manipulation.
User- Who is posting this? Is it a reliable source? Is this account tied to a real-world institution that I trust?
- What is the username length? Is it a long set of random numbers and letters? Is it a verified account? Does it only have a handful of followers (who also look random or not real)?
- Does the framing make sense? What is this content about? Is it especially vague or seems so outrageous that it couldn’t be true? Does this contradict what you already know about the topic?
- Are there platform flags that the content could be potentially misleading, or a comment section full of claims that it’s false? Are there AI badges or indicator hashtags such as #AI, #satire, #skit, #spoof or #AD?
- How is it written? Is there poor or wooden-sounding grammar? Is it flowery? Is there unnatural repetition, or has the user posted the same thing several times?
- Does it repeat often-used AI words such as “elevate,” “captivate,” “tapestry” or “delve”? Does it use known AI phrases such as “provided valuable insights,” an “indelible mark,” or “a rich tapestry”? (Of course, these words and phrases don’t definitively mean that the content is AI-generated misinformation; they’re just reasons to take a closer look.)
- Is this an especially emotion-laded post? Is the level of emotion appropriate for the situation?
- Does the post appear to “weaponize” emotion or tell readers how to feel about the content, such as by using more anger and swear words? (Keep in mind that bots on social media can and do use profanity).
- What might someone have to gain by touching on your emotions in this way? What’s the worst-case scenario if this turns out to not be true? What might a user (using AI) be hoping you don’t look up?
Gone are the days where every AI image looked like a wacky Pixar knockoff, but it’s still worth checking for these known cues:
- Hands and teeth with too many fingers, too many hands, too many teeth or impossibly long arms
- Hyper-realistic images or those that look like paintings
- Texture issues in the background, midground and around the corners and edges of an image
- Unnatural smoothness, especially on faces, clothes or hair
- Shadows and light coming from the wrong place, or with only certain elements casting shadows
- Abrupt transitions, either in an image or a video
Tools like TrueMedia.org scan social posts for false faces, voices, and information, while Mozilla’s Deepfake Detector analyzes text using multiple detection engines and generates a confidence score indicating the likelihood that the content is AI-generated. But while AI detection accuracy is improving, it isn’t perfect.
It always helps to try to verify the information itself — search for it along with “fact check” and look for trusted sources. For images, try a reverse image search using Google Image Search or Bing Image Match.
What can misinformation look like on TikTok?Every social media site has its own AI landscape. Fake news, images and news clips targeting young voters and consumers are circulated particularly widely on TikTok due to its young user base. “Content farms” spin out inaccurate or misleading videos, often multiple a day in the distinctive TikTok style of on-screen text read by an AI voice.
When scrolling on TikTok, be skeptical — or at least get a second opinion — on any informational videos that aren’t read by real people or only consist of captions to the AI voice (reputable news sites usually show who’s talking to build trust). Profiles that look like news sites but that have no comments or likes (especially for celebrity news) are a red flag — as well as canned phrases like “creepy response” or “finally broke their silence” meant to drive clicks.
What can misinformation look like on X?Though many AI-generated posts on X are largely innocuous text-based posts, videos in particular are more likely to be political deepfakes. And while the crowdsourced moderation feature, “Community Notes,” allows users to annotate posts with context or warnings, it replaced a more robust monitoring operation that means it’s more likely users will encounter bots.
Stay wary of accounts that only spam replies, or situations where multiple accounts are commenting similar things under a post. If a user only posts replies, especially to inflammatory content, it’s a red flag that it’s a bot searching for certain keywords.
Also, user verification on X is the least trustworthy of the major social media sites as users can pay for “verified” status (in one Cambridge study, half of synthetic profiles studied had verified status).
What can misinformation look like on Facebook?It’s especially difficult to silo yourself from AI-generated content on Facebook, even if you’re only interested in posts from family and friends. Over the past three years, there has been a “significant increase” in the rate of users seeing posts they held no “friend” connection to, thanks to the algorithm that surfaces high-engagement posts in users’ feeds.
Being disciplined about clicking “not interested” under the three dots on each post can help stem the flow, as well as staying skeptical of images and being wary of link-outs to “news” sites. Verify posts (even those that appear to be from a harmless, real person) about any news events independently.
Misleading posts on Facebook are also especially focused on trying to get users off Facebook — directing them off the platform to content farms, fake stores and other scam sites.
Stay alert and think critically onlineHumans often overestimate how good they are at detecting AI — nice art is sometimes AI-generated, and terrible grammar is sometimes very human. It’s not easy to navigate a landscape designed to trick you, but your best call is to improve how you critically consume all information. Stay curious. After all, AI gets better every passing day — right down to drawing those tricky hands.
Sarah Skinner is a senior editor at a NYC tech startup. She holds a degree from Cornell University on AI and empathy, and has previously worked for McKinsey & Company and the Associated Press.
The post Misinformation in the age of AI: It’s in the details (like extra fingers) appeared first on The Mozilla Blog.
Mozilla’s response to proposed remedies in U.S. v. Google
Last week the Department of Justice and some state attorneys general filed revised proposed remedies in the U.S. v. Google LLC search case. If the proposed remedies barring all search payments to browser developers are adopted by the court, these misguided plans would be a direct hit to small and independent browsers—the very forces that keep the web open, innovative and free. This case was meant to promote search competition, yet somehow the outcome threatens to crush browser competition, making it even harder for challengers to stand up to dominant players like Google, Apple and Microsoft.
“These proposed remedies prohibiting search payments to small and independent browsers miss the bigger picture—and the people who will suffer most are everyday internet users,” said Mark Surman, President of Mozilla. “Independent browsers like Firefox are on the frontlines of protecting consumer privacy, driving browser innovation, and giving people real choice on how they experience the web. But instead of promoting a fair fight, the DOJ’s remedies would tilt the playing field further into the hands of a few dominant players, diminishing consumer choice and weakening the broader internet ecosystem.”
The DOJ’s proposal hurts, not helps, browser competitionMozilla agrees that we need to improve search competition, but the DOJ’s proposed remedies unnecessarily risk harming browser competition instead.
Here’s why:
- The DOJ wants to ban all search agreements between Google and browsers, even independent browsers that make up a smaller part of the market.
- Dominant players that own browsers, like Apple, don’t rely on search deals as they have significant revenue streams from other sources, like hardware, operating systems and app stores.
- Meanwhile, independent browsers like Firefox fund the development of their browsers mainly through search revenue––they require this revenue to survive. Search revenue underpins a large part of our work, keeping Firefox competitive and ensuring that web users have privacy-first alternatives.
- Punishing independent browsers will not solve the problem. Judge Mehta found that independent browsers account for just 1.15% of U.S. search queries. This means that cutting off our access to search deals won’t fix the issue of search dominance—not by a landslide. Instead, it hurts browser competition.
“The big unintended consequence here is the handing of power from one dominant player to another. So, from Google Search to Microsoft, or Bing for example—while shutting out the smaller, independent challengers that actually drive browser innovation and offer web users privacy and choice,” Surman added.
The last unicorn–the web can’t afford to lose Mozilla’s browser engine
Another thing missing from this conversation is something pretty important—browser engine competition.
You see, browser engines power the web. They are central to a browser’s speed, privacy and security functionality, and the browser’s ability to innovate and do things differently. But they’re very complex and require massive resources and a deep technical expertise to maintain—so much so, that right now only three major browser engines remain: Google’s Chromium, Apple’s Webkit (this engine is really only supported on Apple devices, and isn’t considered “cross-platfrom”), and then there’s Mozilla’s Gecko (which happens to be the only true cross-platform alternative to Chromium).
The DOJ’s proposal to bar search payments to independent browser developers would put Mozilla’s ability to develop and maintain Gecko at risk. If Mozilla is unable to sustain our browser engine, it would severely impact browser engine competition and mean the death of the open web as we know it—essentially, creating a web where dominant players like Google and Apple, have even more control, not less.
“This isn’t just about Firefox,” Surman explained. “If we lose our ability to maintain Gecko, it’s game over for an open, independent web. Look, Microsoft—a $3 trillion company—already gave up its browser engine in 2019 and Opera gave up theirs in 2013. If Mozilla is forced out, Google’s Chromium becomes the only cross-platform browser engine left.”
Mozilla’s role in an open web is BIGGER than our market shareNevermind our market share, Mozilla has played an outsized role in keeping the web open, private and advocating for choice. Firefox still serves 27 million monthly active users (MAU) in the U.S. and nearly 205 million MAU globally, but our real impact comes from making the internet better by:
- Shaping the future of web standards—maintaining our own browser engine, Gecko, gives us a voice in defining how the web works and making decisions that are in support of people, not the bottom-line.
- Ensuring interoperability—we fight for a web accessible to all—where anyone can create, access, and share content seamlessly, regardless of the devices or web services they use—not locked into a few ecosystems.
- Proving that privacy-respecting technology is possible—we build critical web technologies with security, privacy and user agency at the core.
“This isn’t something we do because it’s profitable or easy,” said Surman. “We do it because it matters. The DOJ’s proposal doesn’t just miss the mark, it risks handing even more power to dominant industry players like Google or Apple, not less.”
Mozilla calls on regulators and policymakers to recognize the vital role of independent browsers and take action to nurture competition, innovation, and protect the public interest in the evolving digital landscape.
Mozilla is committed to ensuring a fair and competitive internet ecosystem, one where independent browsers can compete on a level playing field and consumers have real choice. The future of competition, innovation and the open internet depends on us.
The post Mozilla’s response to proposed remedies in U.S. v. Google appeared first on The Mozilla Blog.
What is the best hardware concurrency for running inference on CPU?
In the Firefox AI Runtime, we can use multiple threads in the dedicated inference process to speed up execution times CPU. The WASM/JS environment can create a SharedArrayBuffer and run multiple threads against its content and distribute the load on several CPU cores concurrently.
Below is the time taken in seconds on a MacBook M1 Pro, which has 10 physical cores, using our PDF.js image-to-text model to generate an alt text, with different levels of concurrency:

So running several threads is a game-changer ! But using more and more threads will start to slow down execution time to a point where it will become slower than not using threads at all.
So one question we have asked ourselves was: how can we determine the best number of threads ?
Physical vs logical coresAccording to our most recent public data report, on desktop, 81% of our users are equipped with an Intel CPU, 14% with AMD and the rest are mostly Apple devices.
All modern CPUs provide more logical cores (also called “threads”) than physical cores. This happens due to technologies like Intel’s Hyper-Threading. Or AMD’s Simultaneous Multithreading (SMT).
For example, the Intel Core i9-10900K chip has 10 physical cores and 20 logical cores.
When you spin up threads equal to the number of logical cores, you might see performance gains, especially when tasks are I/O bound or if the CPU can effectively interleave instructions.
However, for compute-bound tasks (like heavy ML inference), having more threads than physical cores can lead to diminishing returns, or even performance drops, due to factors like thread scheduling overhead and cache contention.
Not all cores are created equalOn Apple Silicon, you don’t just have a quantity of cores; you have different kinds of cores. Some are high-performance cores designed for heavy lifting, while others are efficiency cores that are optimized for lower power consumption.
For instance, Apple M1 Pro chips have a combination of high-performance (8) and efficiency cores (2). The physical cores might total 10, but each performance core is designed for heavy-duty tasks, while efficiency cores typically handle background tasks that are less demanding.
When your machine is under load with ML tasks, it’s often better to fully utilize the high-performance cores and leave some breathing room for the efficiency cores to handle background or system processes.
Similarly, Intel’s processors have different cores, most notably starting with their 12th-generation “Alder Lake” architecture.
These chips feature Performance-cores (P-cores) designed for demanding, single-threaded tasks, and Efficient-cores (E-cores) aimed at background or less intensive workloads. The P-cores can leverage Intel’s Hyper-Threading technology (meaning each P-core can run two logical threads), while E-cores typically run one thread each. This hybrid approach enables the CPU to optimize power usage and performance by scheduling tasks on the cores best suited for them. Like Apple Silicon’s you’d typically want to maximize utilization of the higher-performance P-cores, while leaving some headroom on the E-cores for system processes.
Android is close to Apple Silicon’s architecture, as most devices are using ARM’s big.LITTLE (or DynamIQ) architecture – with 2 types of cores: “big” and “LITTLE”.
On mobile Qualcomm’s CPU, there can be three types: “Prime”, “Performance” and “Efficiency”. Most recently, some phones like Samsung Galaxy S24 have gained a fourth kind of core (Exynos 2400) allowing even more combinations.
To summarize, all CPU makers have cores dedicated to performance, and cores for efficiency:
- Performance: “P-Core”, “big”, “Prime”, “Performance”
- Efficiency: “E-Core”, “LITTLE”, “Efficiency”
By combining high-efficiency and high-performance cores, Apple Silicon, Androids, and Intel based devices can strike a better balance between power consumption and raw compute power, depending on the demands of the workload.
But if you try to run all cores (performance + efficiency) at maximum capacity, you may see:
- Less optimal thread scheduling, because tasks will bounce between slower efficiency cores and faster performance cores.
- Contention for shared resources like the memory bus, cache.
- And in extreme cases: thermal throttling if the system overheats, and reaches its Thermal Design Point, in which case the clock speed is throttled to cool down the system.
This is why simply setting the thread count to “all cores, all the time” can be suboptimal for performance.
AMD on the other hand, does not have efficiency cores. Some CPUs like the Ryzen 5 8000 combine two sizes of cores Zen 4 and Zen 4c, but the latter is not an efficiency core and can also be used to run heavy-duty tasks.
navigator.hardwareConcurrencyIn a browser, there is a single and simple API you can call: navigator.hardwareConcurrency
This returns the number of logical cores available. Since it’s the only API available on the web, many libraries (including the one we vendor: onnxruntime) default to using navigator.hardwareConcurrency as a baseline for concurrency.
It’s bad practice to use that value directly as it might overcommit threads as we’ve explained in the previous sections. It’s also not aware of the current system’s activity.
For that reason, ONNX formula takes the number of logical cores divided by two and will never set it higher than 4:
Math.min(4, Math.ceil((navigator.hardwareConcurrency || 1) / 2));That formula works out ok in general, but will not take advantage of all the cores for some devices. For instance, on an Apple M1 Pro, ML tasks could use a concurrency level up to 8 cores instead of 4.
On the other end of the spectrum, a chip like Intel’s i3-1220p that we use in our CI to run tests in Windows 11, which reflects better what our users have – see our hardware section in our Firefox Public Data Report.
It has 12 logical cores and 10 physical cores that are composed of 8 efficient cores and 2 performance cores. ONNX formula for that chip means we would run with 4 threads, where 2 would be a better value.
navigator.hardwareConcurrency is a good starting point, but it’s just a blunt instrument. It won’t always yield the true “best” concurrency for a given device and a given workload.
MLUtils.getOptimalCPUConcurrencyWhile it’s impossible to get the best value at any given time without considering the system activity as a whole, looking at the number of physical cores and not using “efficiency” cores, can help to get to a better value.
Llama.cpp for instance is looking at the number of physical cores to decide for concurrency, with a few twists:
- On any x86_64, it will return the number of performance cores
- On Android, and any aarch64-based devices like Apple Silicon it will return the number of performance cores for tri-layered chips.
We’ve implemented something very similar in a C++ API that can be used via XPIDL in our inference engine:
NS_IMETHODIMP MLUtils::GetOptimalCPUConcurrency(uint8_t* _retval) { ProcessInfo processInfo = {}; if (!NS_SUCCEEDED(CollectProcessInfo(processInfo))) { return NS_ERROR_FAILURE; } #if defined(ANDROID) // On android, "big" and "medium" cpus can be used. uint8_t cpuCount = processInfo.cpuPCount + processInfo.cpuMCount; #else # ifdef __aarch64__ // On aarch64 (like macBooks) we want to avoid efficient cores and stick with "big" cpus. uint8_t cpuCount = processInfo.cpuPCount; # else // on x86_64 we're always using the number of physical cores. uint8_t cpuCount = processInfo.cpuCores; # endif #endif *_retval = cpuCount; return NS_OK; }This function is then straightforward to use from JS shipped within Firefox to configure concurrency when we run inference:
let mlUtils = Cc["@mozilla.org/ml-utils;1"].createInstance(Ci.nsIMLUtils); const numThreads = mlUtils.getOptimalCPUConcurrency();We’ve moved away from using navigator.hardwareConcurrency, and we’re now using this new API.
ConclusionIn our quest to find the optimal number of threads, we’re closer to reality now, but there are other factors to consider. The system will use the CPU for other applications so it’s still possible to overload it.
Using more threads is also going to use more memory in our WASM environment, which can become a real issue. Depending on the workload, each additional thread can add up to 100MiB of physical memory usage in our runtime. We’re working on reducing this overhead but on devices that don’t have a lot of memory, limiting concurrency is still our best option.
For our Firefox ML features, we are using a variety of hardware profiles in our performance CI to make sure that we try them on devices that are close to what our users have. The list of devices we have is going to grow in the next few months to make sure we cover the whole spectrum of CPUs. We’ve started collecting and aggregating metrics on a dashboard that helps us understand what can be expected when our users run our inference engine.
The hardware landscape is also evolving a lot. For example, the most recent Apple devices introduced a new instruction set, called AMX, which used to be proprietary, and gave a significant boost compared to Neon. That has now been replaced by an official API called SME. Similarly, some phones are getting more core types, which could impact how we calculate the number of cores to use. Our current algorithm could be changed the day we leverage these new APIs and hardware in our backend.
Another aspect we have not discussed in this post is using GPU or even more specialized units like NPUs, to offload our ML tasks, which will be a post on its own.
The post What is the best hardware concurrency for running inference on CPU? appeared first on The Mozilla Blog.
Pagina's
- 1
- 2
- 3
- 4
- volgende ›
- laatste »